上一篇笔记中我们介绍的 bridge 网络模型主要用于解决同一主机间的容器相互访问以及容器对外暴露服务的问题,并没有涉及到怎么解决跨主机的容器之间互相访问的问题。
对于跨主机容器间的相互访问问题,我们能想到的最直观的解决方案就是直接使用宿主机网络,这时,容器完全复用复用宿主机的网络设备以及协议栈,容器 IP 就是主机 IP,这样,只要宿主机主机能通信,容器也就自然能通信。但是这样,为了暴露容器服务,每个容器需要占用宿主机上的一个端口,通过这个端口和外界通信。所以,就需要手动维护端口的分配,而且不能使不同的容器服务运行在一个端口上,正因为如此,这种容器网络模型很难被推广到生产环境。
因此解决跨主机通信的可行方案主要是让容器配置与宿主机不一样的 IP 地址,往往是在现有二层或三层网络之上再构建起来一个独立的 overlay 网络,这个网络通常会有自己独立的 IP 地址空间、交换或者路由的实现。由于容器有自己独立配置的 IP 地址,underlay 平面的底层网络设备如交换机、路由器等完全不感知这些 IP 的存在,也就导致容器的 IP 不能直接路由出去实现跨主机通信。
为了解决容器独立 IP 地址间的访问问题,主要有以下两个思路:
修改底层网络设备配置,加入容器网络 IP 地址的管理,修改路由器网关等,该方式主要和 SDN(Software define networking) 结合。
完全不修改底层网络设备配置,复用原有的 underlay 平面网络解决容器跨主机通信,主要有如下两种方式:
- 隧道传输(overlay):将容器的数据包封装到宿主机网络的三层或者四层数据包中,然后使用宿主机的 IP 或者 TCP/UDP 传输到目标主机,目标主机拆包后再转发给目标容器。overlay 隧道传输常见方案包括 VxLAN、ipip 等,目前使用 Overlay 隧道传输技术的主流容器网络有 Flannel 等。
- 修改主机路由:把容器网络加到宿主机网络的路由表中,把宿主机网络设备当作容器网关,通过路由规则转发到指定的主机,实现容器的三层互通。目前通过路由技术实现容器跨主机通信的网络如 Flannel host-gw、Calico 等。
技术术语
在开始之前,我们总结一些在容器网络介绍文章里面经常看到各种技术术语:
- IPAM(IP Address Management):即 IP 地址管理。IPAM 并不是容器时代特有的词汇,传统的标准网络协议比如 DHCP 其实也是一种 IPAM,负责从 MAC 地址分发 IP 地址;但是到了容器时代我们提到 IPAM,我们特指为每一个容器实例分配和回收 IP 地址,保证一个集群里面的所有容器都分配全局唯一的 IP 地址;主流的做法包括:基于 CIDR 的 IP 地址段分配地或精确为每一个容器分配 IP;
- overlay:在容器时代,就是在主机现有二层(数据链路层)或三层(IP 网络层)基础之上再构建起来一个独立的网络平面,这个 overlay 网络通常会有自己独立的 IP 地址空间、交换或者路由的实现;
- IPIP:一种基于 Linux 网络设备 TUN 实现的隧道协议,允许将三层(IP)网络包封装在另外一个三层网络包之上发送和接收,详情请看揭秘 IPIP 隧道;
- IPSec:跟 IPIP 隧道协议类似,是一种点对点的加密通信协议,一般会用到 overlay 网络的数据隧道里;
- VxLAN:最主要是解决 VLAN 支持虚拟网络数量(4096)过少的问题而由 VMware、Cisco、RedHat 等联合提出的解决方案;VxLAN 可以支持在一个 VPC(Virtual Private Cloud) 划分多达1600万个虚拟网络;
- BGP:主干网自治网络的路由协议,当代的互联网由很多小的 AS(Autonomous system)自治网络构成,自治网络之间的三层路由是由 BGP 协议实现的,简单来说,通过 BGP 协议 AS 告诉其他 AS 自己子网里都包括哪些 IP 地址段,自己的 AS 编号以及一些其他的信息;
- SDN(Software-Defined Networking):一种广义的概念,通过软件方式快速配置网络,往往包括一个中央控制层来集中配置底层基础网络设施;
docker 原生 overlay
docker 原生支持 overlay 网络用来解决容器间的跨主机通信问题,事实上,对于 docker 原生支持的 overlay 网络,Laurent Bernaille 在 DockerCon 2017上详细剖析了它的实现原理,甚至还有从头开始一步步实现该网络模型的实践教程,这三篇文章为:
- Deep dive into docker overlay networks part 1
- Deep dive into docker overlay networks part 2
- Deep dive into docker overlay networks part 3
所以在这里我就只是大致介绍一下 docker 原生 overlay 网络模型的大致原理:
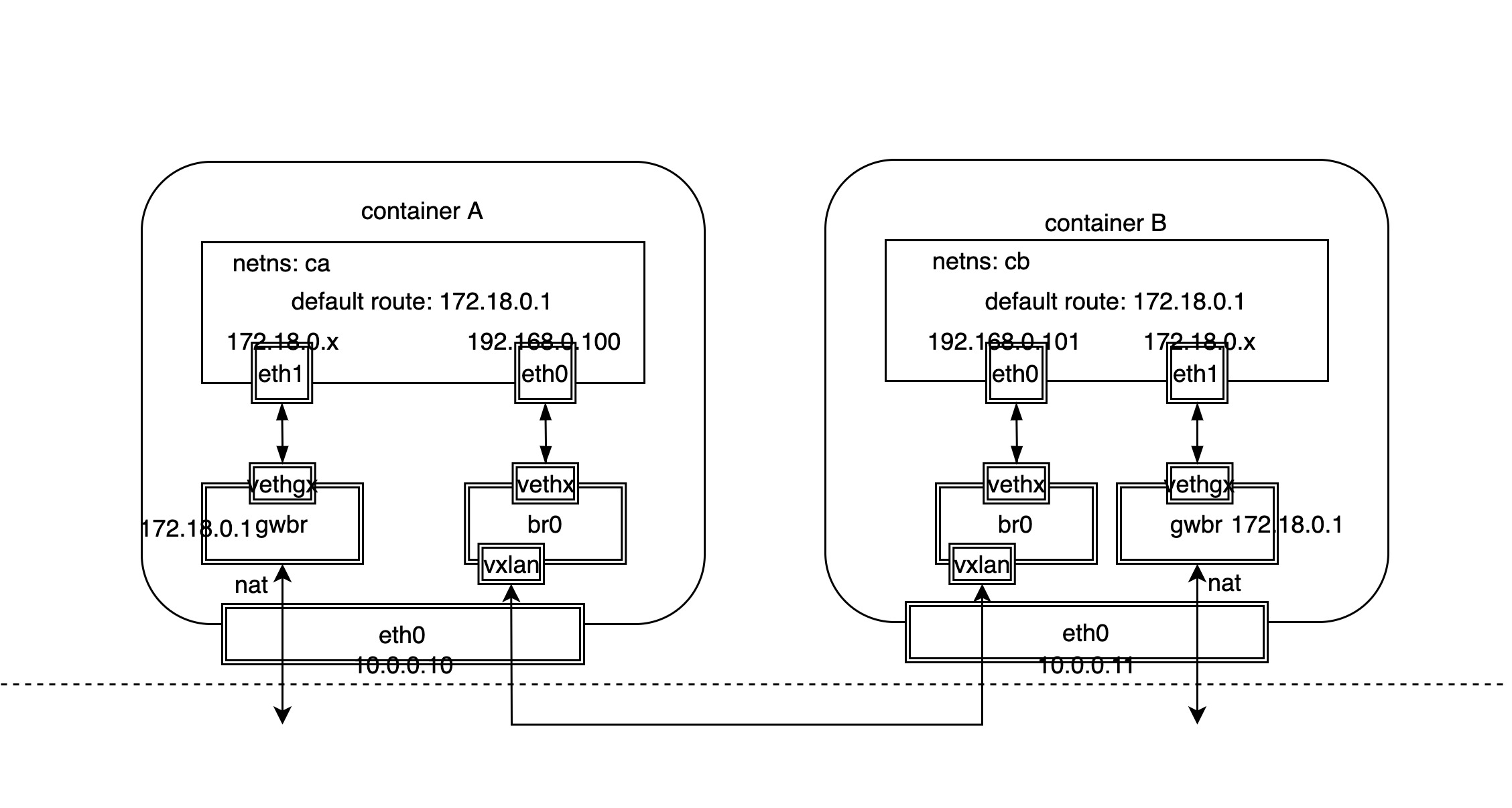
从上面的网络模型图可以看出,对于 docker 原生 overlay 网络来说,处理容器对外访问的南北流量和容器之间相互访问的东西流量分别使用不同的 Linux 网络设备:
- 南北流量:类似于 bridge 网络模型,通过主机的网桥设备充当网关,然后使用 veth 设备对分别连接主机网桥和容器内网卡设备,最后通过主机网卡发送接收对外的数据包,需要注意的是,对外数据包需要做地址转化;
- 东西流量:另外在主机上单独增加一个网桥设备,然后使用 veth 设备对分别连接主机网桥和容器内网卡设备,同时主机内网桥设备还绑定了 VxLAN 设备,VxLAN 设备将跨主机的容器数据包封装成 VxLAN 数据包发送到目标主机,然后解封装后转发给对应的容器;
需要注意的是,虽然跨主机的两个容器是通过 overlay 网络通信的,但容器自己不能感知,因为它们只认为彼此都在一个子网中,只需要知道对方的 MAC 地址,可以通过 ARP 协议广播学习获取 IP 与 MAC 地址转换。当然通过 VxLAN 隧道广播 ARP 包理论上也没有问题,问题是该方案将导致广播包过多,广播的成本会很大。
docker 给出的方案是通过** ARP 代理+静态配置**解决 ARP 广播问题,容器的地址信息保存到到 KV 数据库 etcd 中。这样就可以通过静态配置的方式填充 IP 和 MAC 地址表(neigh表)替换使用 ARP 广播的方式,所以 VxLAN 设备还负责本地容器的 ARP 代理:
# ip link show VxLAN0 | grep proxy_arp
# ip neigh
192.168.0.103 dev VxLAN0 lladdr 02:42:0a:14:00:03 PERMANENT
192.168.0.104 dev VxLAN0 lladdr 02:42:0a:14:00:04 PERMANENT
上面 neign 信息中的 PERMANENT 代表静态配置而不是通过学习获取的,而192.168.0.103和192.168.0.104是另外两个容器的 IP 地址。每当有新的容器创建时,docker 通过通知节点更新本地 neigh 信息表。
另外,容器之间的数据包最终还是通过 VxLAN 隧道传输的,因此需要知道数据包的目标容器在哪个节点。当节点数量达到一定数量级之后,如果采用和 ARP 一样的广播洪泛的方式学习,那么显然同样存在性能问题,实际上也很少使用这种方案,在硬件 SDN 中通常使用 BGP EVPN 技术实现 VxLAN 的控制平面,而 docker 解决的办法和 ARP 类似,通过静态配置的方式填充 VTEP(VxLAN Tunnel Endpoint)表,我们可以查看容器网络命名空间的转发表(FDB: Forward DataBase):
# bridge fdb
...
82:fa:1d:48:14:04 dev VxLAN0 dst 10.0.0.10 link-netnsid 0 self permanent
82:fa:1d:48:14:05 dev VxLAN0 dst 10.0.0.11 link-netnsid 0 self permanent
上面的转发表信息表示 MAC 地址82:fa:1d:48:14:04的对端 VTEP 地址为10.0.0.10,而82:fa:1d:48:14:04的对端 VTEP 地址为10.0.0.10,permanent 说明这两条转发表记录都是静态配置的,而这些数据来源依然是 KV 数据库 etcd,这些 VTEP 地址为容器所在的主机的 IP 地址。
Flannel
Flannel 是目前最主流的容器网络实现模型之一,同时支持 overlay 和修改主机路由两种模式。
Flannel 和 docker 原生 overlay 网络不同的是,后者的所有节点共享一个子网,而 Flannel 初始化时通常指定一个16位的网络,然后每个节点单独分配一个独立的24位子网。由于节点都在不同的子网中,跨节点通信本质为三层通信,也就不存在二层的 ARP 广播问题了。
另外,Flannel 之所以被认为非常简单优雅的是,不像 docker 原生 overlay 网络需要在容器内部再增加一个网桥设备专门用于 overlay 网络的通信,Flannel 只需要使用 docker 最原生的 docker0 网络,除了需要为每个节点配置子网外,几乎不改变原有的 docker 网络模型。
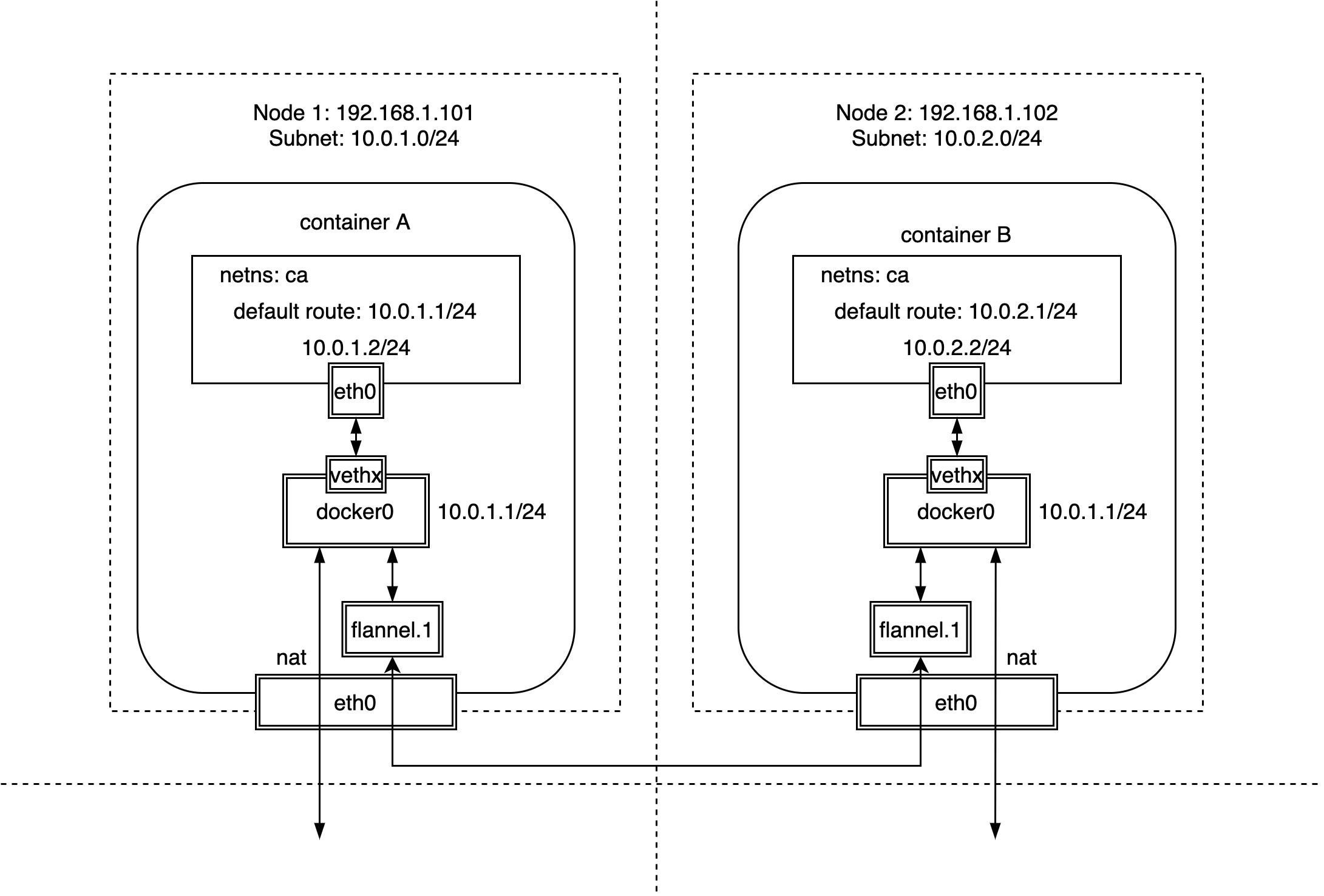
正如上面这张图看到的那样,Flannel 在 docker 最原生的 docker0 网桥设备和 veth 设备对的基础上,为了每个节点单独分配了一个子网:
| Node Name | Node IP | Node Subnet |
|---|---|---|
| Node 1 | 192.168.1.101 | 10.0.1.0/24 |
| Node 2 | 192.168.1.102 | 10.0.2.0/24 |
我们也可以看到,容器对外流量的访问以及同一主机上的容器之间的访问完全与 docker 原生的 bridge 模式相同。那么,怎么实现跨主机间的容器相互访问呢?
前面说过,Flannel 同时提供了 overlay 和修改主机路由两种方式,其中 overlay 方式主要通过 VxLAN 隧道,而修改主机路由则是通过配置主机静态路由的方式。
VxLAN 隧道
查看主机 node1 的本地静态路由:
# node1
# ip route show
...
10.0.1.0/24 dev docker0 proto kernel scope link src 10.0.1.1
10.0.2.0/24 via 10.0.2.0 dev flannel.1 onlink
# node2
# ip route show
...
10.0.2.0/24 dev docker0 proto kernel scope link src 10.0.2.1
10.0.1.0/24 via 10.0.1.0 dev flannel.1 onlink
可以看到,对于每个主机,当前子网都可以直接通过 docker0 网桥直接访问,而其他的子网则需要特殊的网络设备 flannel.1 来访问,它是一个 Linux 的 VxLAN 网络设备,其中.1为 VNI 值,默认值为1。
因为同一主机的容器处于同一子网,因此直接通过 ARP 学习即可得到,而不同主机上的容器处于不同的子网,所以不涉及 ARP 广播泛洪的问题。但是,VxLAN 网络设备 flannel.1 如何知道对端 VTEP 地址呢?我们来看一下转发表 FDB:
# bridge fdb | grep flannel
82:fa:1d:48:14:00 dev flannel.1 dst 192.168.1.102 self permanent
其中192.168.1.102是另外一个节点的 IP 地址,即 VTEP 地址,而82:fa:1d:48:14:00是对端网络设备 flannel.1 的 MAC 地址,从 permanent 可以看出转发表是由 Flannel 静态添加的,这些信息可以保存在 etcd 中。
相对于 docker 原生的 overlay 网络来说,除了增加或者减少节点,需要 Flannel 配合配置静态路由以及转发表 FDB,容器的创建与删除完全不需要 Flannel 的干预,事实上 Flannel 也不需要知道有没有新的容器创建或者删除。
host-gw 路由
上面我们介绍了 Flannel 通过 VxLAN 隧道搭建 overlay 网络实现容器间的跨主机通信,其实 Flannel 也支持通过 host-gw,也就是修改主机路由的方式实现容器间的跨主机通信,此时每个节点都相当于一个路由器,作为容器的网关,负责容器之间网络包的路由转发。
对于 Flannel 的 host-gw 修改主机路由的实现方式,我们后面有机会再详细去剖析。需要说明的是 host-gw 的方式相对 overlay 由于少了 VxLAN 的封包拆包过程,直接路由数据包到目的地址,因此性能相对要好。不过正是由于它是通过添加静态路由的方式实现,每个宿主机相当于是容器的网关,因此每个宿主机必须在同一个子网内,否则跨子网由于链路层不通导致无法实现路由。
Calico
Calico 采用和 Flannel 修改主机路由 host-gw 类似的方式来实现容器间的跨主机通信,不同的地方在于 Flannel 通过 flanneld 进程逐一添加主机静态路由实现,而 Calico 则是通过 BGP 协议实现节点间路由规则的相互学习广播。
Calico 也会像 Flannel 一样会为每个主机节点分配一个子网,只不过 Calico 默认分配的是26位子网,不同于 Flannel 默认分配的24位子网:
| Node Name | Node IP | Node Subnet |
|---|---|---|
| Node 1 | 172.16.31.155 | 10.1.83.192/26 |
| Node 2 | 172.16.32.117 | 10.1.32.192/26 |
| Node 2 | 172.16.32.120 | 10.1.147.128/26 |
Calico 通过 BGP 协议动态调整路由,那么我们就来看看主机的路由规则:
# node1
# ip route show
...
blackhole 10.1.83.192/26 proto bird
10.1.83.193 dev cali8632426305e scope link
10.1.83.194 dev cali87c063cc2db scope link
10.1.32.192/26 via 172.16.32.117 dev tunl0 proto bird onlink
10.1.147.128/26 via 172.16.32.120 dev tunl0 proto bird onlink
可以看到,Calico 修改主机路由来实现容器间的跨主机通信方式和 Flannel host-gw 一样,下一跳直接指向对应主机的 IP,把主机当作容器的网关。但 Calico 会增加一条 blackhole 规则,将对非法的容器 IP 的访问数据包直接丢弃;另外一个不一样的地方是数据包到达宿主机后,Flannel 会通过路由转发流量到 bridge 网络设备中,再由 bridge 设备转发给容器,而 Calico 则为每个容器 IP 生成一条路由规则,直接指向容器的网卡对端。当容器数量达到一定规模之后,主机路由规则数量也会越来越多,性能会是个问题。Calico 给出的解决方案是路由反射器(route reflector)。
此外,需要注意的是,我们知道 Flannel host-gw 的方式只支持每个宿主机在同一个子网内,才可以添加静态路由规则,不能支持跨网段的主机,那么 Calico 支持吗?
答案是肯定的,Calico 在安装的时候可以指定是否打开 ipip 模式,也就是 ipip 隧道。在我的实验环境中,ipip 模式已经打开,如果你观察得够仔细的话,你会发现主机路由中发往其他主机上的容器的路由要经过 tunl0 网络设备,我们来看一下 tunl0 网络设备的类型:
# ip link show tunl0
5: tunl0@NONE: <NOARP,UP,LOWER_UP> mtu 1430 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1
link/ipip 0.0.0.0 brd 0.0.0.0
可以看到,tunl0 其实是 Linux 的 TUN 网络设备,它会在不同主机节点间开启 IPIP 隧道,也就是说,即使主机节点处于三层网络中,数据包还是可以通过隧道发送到目标主机,再由目标主机转发给对应的容器,此时 Calico 其实采用的是 overlay 的实现方式。