容器网络需要解决的两大核心问题是:
- 容器 IP 地址的管理
- 容器之间的相互通信
其中,容器 IP 地址的管理包括容器 IP 地址的分配与回收,而容器之间的相互通信包括同一主机容器之间和跨主机容器之间通信两种场景。这两个问题也不能完全分开来看,因为不同的解决方案往往要同时考虑以上两点。
容器网络的发展已经相对成熟,这篇笔记先对主流容器网络模型做一些概述,然后将进一步对典型的容器网络模型展开实践。
CNM vs CNI
关于容器网络,docker 与 kubernetes 分别提出了不同的规范标准:
CNM 基于 libnetwork,是 docker 内置的模型规范,它的总体架构如下图所示:
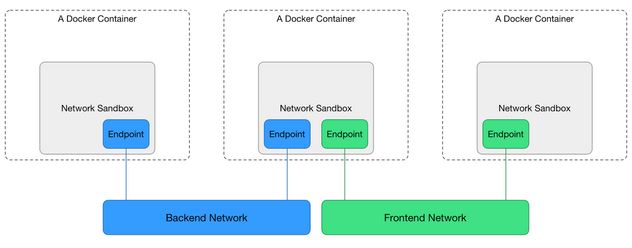
可以看到,CNM 规范主要定义了以下三个组件:
- Sandbox: 每个 Sandbox 包一个容器网络栈(network stack)的配置:容器的网口、路由表和 DNS 设置等,Sanbox 可以通过 Linux 网络命名空间 netns 来实现;
- Endpoint: 每个 Sandbox 通过 Endpoint 加入到一个 Network 里,Endpoint 可以通过 Linux 虚拟网络设备 veth 对来实现;
- Network: 一组能相互直接通信的 Endpoint,Network 可以通过 Linux网桥设备 bridge 或 VLAN 等实现
可以看到,底层实现原理还是我们之前介绍过的 Linux 虚拟网络设备、网络命名空间等。CNM 规范的典型场景是这样的:用户可以创建一个或多个 Network,一个容器 Sandbox 可以通过 Endpoint 加入到一个或多个 Network,同一个 Network 中容器 Sanbox 可以通信,不同 Network 中的容器 Sandbox 隔离。这样就可以实现从容器与网络的解耦,也就是锁,在创建容器之前,可以先创建网络,然后决定让容器加入哪个网络。
但是,为什么 kubernetes 没有采用 CNM 规范标准,而是选择 CNI,感兴趣的话可以去看看 kubernetes 的官方博客 Why Kubernetes doesn’t use libnetwork,总的来说,不使用 CNM 最关键的一点是,是因为 kubernetes 考虑到 CNM 在一定程度上和容器运行时的耦合度太高,因此以 kubernetes 为领导的其他一些组织开始制定新的 CNI 规范。CNI 并不是 docker 原生支持的,它是为容器技术设计的通用型网络接口,因此 CNI 接口可以很容易地从高层向底层调用,但从底层到高层却不是很方便,所以一些常见的 CNI 插件很难在 docker 层面激活。但是这两个模型全都支持插件化,也就是说我们每个人都可以按照这两套网络规范来编写自己的具体网络实现。
docker 通过 libnetwork 原生支持的网络模型可以通过 docker network ls 来列出:
# docker network ls
NETWORK ID NAME DRIVER SCOPE
f559b082c95f bridge bridge local
5f11ccbbf488 host host local
97aedfe8792d none null local
可以看到默认 docker 支持三种网络模型,在创建容器的时候可以通过 --network 来指定使用的网络模型。其中 bridge 是默认值,我们接下来将会介绍并模拟实现 bridge 网络模型;none 网络模型不创建任何网络;host 网络模型就是使用主机网络,它不会创建新的网络命名空间。
Note: 如果打开了 docker swarm,那么你还会看到 overlay 网络模型,后面我们会详细地介绍 docker 原生 overlay 网络模型的实现原理。
bridge 网络
bridge 桥接网络是 docker 默认的网络模型,如果我们在创建容器的时候不指定网络模型,则默认使用 bridge 模型。bridge 网络模型可以解决单宿主机上的容器之间的通信以及容器服务对外的暴露的问题,其实现原理也很简单:
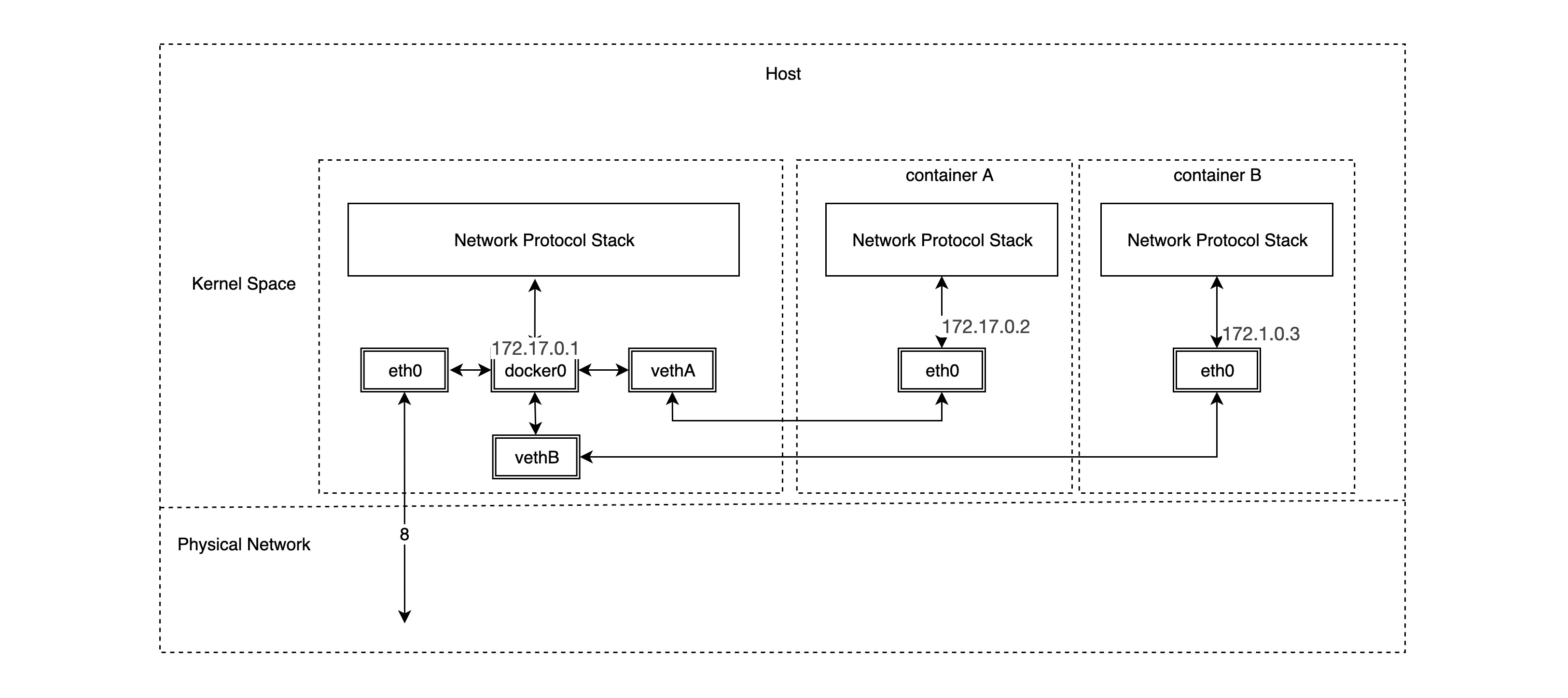
可以看到,bridge 网络模型主要依赖于大名鼎鼎的 docker0 网桥以及 veth 虚拟网络设备对实现,通过之前笔记对于 Linux 虚拟网络设备的了解,我们知道 veth 设备对中从一端 veth 设备发出的数据包,会直接发送到另一端的 veth 设备上,即使不在一个网络命名空间中,所以 veth 设备对实际上是连接不同网络命名空间的“网线”。docker0 网桥设备充当不同容器网络的网关,事实上,我们一旦以 bridge 网络模式创建容器时,会自动创建相应的 veth 设备对,其中一端连接到 docker0 网桥,另外一端连接到容器网络的 eth0 虚拟网卡。
首先我们在安装了 docker 的宿主机上查看网桥设备 docker0 和路由规则:
# ip link show docker0
4: docker0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:59:c8:67:c0 brd ff:ff:ff:ff:ff:ff
# ip route ls
...
172.17.0.0/16 dev docker0 proto kernel scope link src 172.17.0.1
然后使用默认的 bridge 网络模型创建一个容器,并查看宿主机端的 veth 设备对:
# docker run -d --name mynginx nginx:latest
# ip link show type veth
11: veth42772d8@if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue master docker0 state UP mode DEFAULT group default
link/ether e2:a3:89:76:14:f3 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# bridge link
11: veth42772d8 state UP @if10: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 master docker0 state forwarding priority 32 cost 2
可以看到新的 veth 设备对的一端 veth42772d8 已经连接到 docker0 网桥,那么另外一端呢?
# ls /var/run/docker/netns/
62fd67d9ef3e default
# nsenter --net=/var/run/docker/netns/62fd67d9ef3e ip link show type veth
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# nsenter --net=/var/run/docker/netns/62fd67d9ef3e ip addr show type veth
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
正如我们设想的那样,veth 设备对的另外一端处于新的网络命名空间 62fd67d9ef3e 中,并且 IP 地址为172.17.0.2/16,与 docker0 处于同一子网中。
Note: 如果我们创建了映射到
/var/run/docker/netns/的符号链接/var/run/netns,就不用使用 nsenter 命令或者进入容器内部查看 veth 设备对的另外一端,直接使用如下 iproute2 工具包即可以查看:
# ip netns show
62fd67d9ef3e (id: 0)
default
# ip netns exec 62fd67d9ef3e ip link show type veth
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP mode DEFAULT group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
# ip netns exec 62fd67d9ef3e ip addr show type veth
10: eth0@if11: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default
link/ether 02:42:ac:11:00:02 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.17.0.2/16 brd 172.17.255.255 scope global eth0
valid_lft forever preferred_lft forever
bridge 网络模拟
我们接下来就模拟一下 bridge 网络模型的实现,基本的网络拓扑图如下所示:
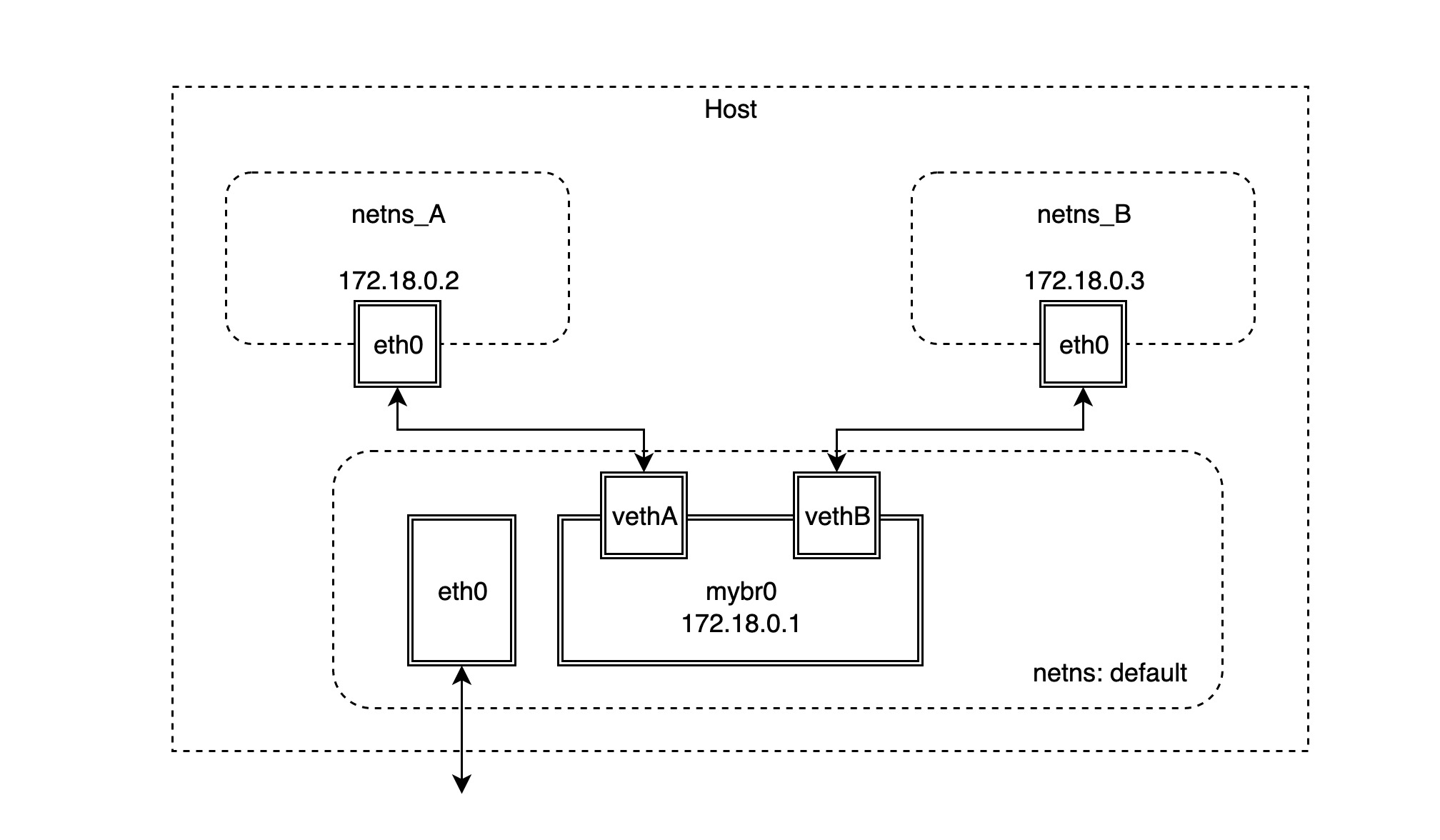
- 首先创建两个 netns 网络命名空间:
# ip netns add netns_A
# ip netns add netns_B
# ip netns
netns_B
netns_A
default
- 在 default 网络命名空间中创建网桥设备 mybr0,并分配 IP 地址
172.18.0.1/16使其成为对应子网的网关:
# ip link add name mybr0 type bridge
# ip addr add 172.18.0.1/16 dev mybr0
# ip link show mybr0
12: mybr0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/ether ae:93:35:ab:59:2a brd ff:ff:ff:ff:ff:ff
# ip route
...
172.18.0.0/16 dev mybr0 proto kernel scope link src 172.18.0.1
- 接下来,创建 veth 设备对并连接在第一步创建的两个网络命名空间:
# ip link add vethA type veth peer name vethpA
# ip link show vethA
14: vethA@vethpA: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether da:f1:fd:19:6b:4a brd ff:ff:ff:ff:ff:ff
# ip link show vethpA
13: vethpA@vethA: <BROADCAST,MULTICAST> mtu 1500 qdisc noop state DOWN mode DEFAULT group default qlen 1000
link/ether 86:d6:16:43:54:9e brd ff:ff:ff:ff:ff:ff
- 将上一步创建的 veth 设备对的一端 vethA 连接到 mybr0 网桥并启动:
# ip link set dev vethA master mybr0
# ip link set vethA up
# bridge link
14: vethA state LOWERLAYERDOWN @vethpA: <NO-CARRIER,BROADCAST,MULTICAST,UP> mtu 1500 master mybr0 state disabled priority 32 cost 2
- 将 veth 设备对的另一端 vethpA 放到网络命名空间 netns_A 中并配置 IP 启动:
# ip link set vethpA netns netns_A
# ip netns exec netns_A ip link set vethpA name eth0
# ip netns exec netns_A ip addr add 172.18.0.2/16 dev eth0
# ip netns exec netns_A ip link set eth0 up
# ip netns exec netns_A ip addr show type veth
13: eth0@if14: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 86:d6:16:43:54:9e brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.2/16 scope global eth0
valid_lft forever preferred_lft forever
- 现在就可以验证从 netns_A 网络命名空间中访问 mybr0 网关:
# ip netns exec netns_A ping -c 2 172.18.0.1
PING 172.18.0.1 (172.18.0.1) 56(84) bytes of data.
64 bytes from 172.18.0.1: icmp_seq=1 ttl=64 time=0.096 ms
64 bytes from 172.18.0.1: icmp_seq=2 ttl=64 time=0.069 ms
--- 172.18.0.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1004ms
rtt min/avg/max/mdev = 0.069/0.082/0.096/0.016 m
- 若想要从 netns_A 网络命名空间中访问非
172.18.0.0/16的地址,就需要增加一条默认默认路由:
# ip netns exec netns_A ip route add default via 172.18.0.1
# ip netns exec netns_A ip route
default via 172.18.0.1 dev eth0
172.18.0.0/16 dev eth0 proto kernel scope link src 172.18.0.2
Note: 如果你此时尝试去 ping 其他的公网地址,例如
google.com,是 ping 不通的,原因是 ping 出去的数据包(ICMP 包)的源地址没有做源地址转换(snat),导致 ICMP 包有去无回;docker是通过设置 iptables 实现源地址转换的。
- 接下来,按照上述步骤创建连接 default 和 netns_B 网络命名空间 veth 设备对:
# ip link add vethB type veth peer name vethpB
# ip link set dev vethB master mybr0
# ip link set vethB up
# ip link set vethpB netns netns_B
# ip netns exec netns_B ip link set vethpB name eth0
# ip netns exec netns_B ip addr add 172.18.0.3/16 dev eth0
# ip netns exec netns_B ip link set eth0 up
# ip netns exec netns_B ip route add default via 172.18.0.1
# ip netns exec netns_B ip add show eth0
15: eth0@if16: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc noqueue state UP group default qlen 1000
link/ether 0e:2f:c6:de:fe:24 brd ff:ff:ff:ff:ff:ff link-netnsid 0
inet 172.18.0.3/16 scope global eth0
valid_lft forever preferred_lft forever
# ip netns exec netns_B ip route show
default via 172.18.0.1 dev eth0
172.18.0.0/16 dev eth0 proto kernel scope link src 172.18.0.3
- 默认情况下 Linux 会把网桥设备 bridge 的转发功能禁用,所以在 netns_A 里面是 ping 不通 netns_B 的,需要额外增加一条 iptables 规则才能激活网桥设备 bridge 的转发功能:
# iptables -A FORWARD -i mybr0 -j ACCEPT
- 现在就可以验证两个网络命名空间之间可以互通:
# ip netns exec netns_A ping -c 2 172.18.0.3
PING 172.18.0.3 (172.18.0.3) 56(84) bytes of data.
64 bytes from 172.18.0.3: icmp_seq=1 ttl=64 time=0.091 ms
64 bytes from 172.18.0.3: icmp_seq=2 ttl=64 time=0.093 ms
--- 172.18.0.3 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1027ms
rtt min/avg/max/mdev = 0.091/0.092/0.093/0.001 ms
# ip netns exec netns_B ping -c 2 172.18.0.2
PING 172.18.0.2 (172.18.0.2) 56(84) bytes of data.
64 bytes from 172.18.0.2: icmp_seq=1 ttl=64 time=0.259 ms
64 bytes from 172.18.0.2: icmp_seq=2 ttl=64 time=0.078 ms
--- 172.18.0.2 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1030ms
rtt min/avg/max/mdev = 0.078/0.168/0.259/0.091 ms
实际上,此时两个网络命名空间处于同一个子网中,所以网桥设备 mybr0 还是工作在二层(数据链路层),只需要对方的 MAC 地址就可以访问。
但是如果需要从两个网络命名空间访问其他网段的地址,这个时候网桥设备 mybr0 设置为默认网关地址就发挥作用了:来自于两个网络命名空间的数据包发现目标 IP 地址并不是本子网地址,于是发给网关 mybr0,此时网桥设备 mybr0 其实工作在三层(IP网络层),它收到数据包之后,查看本地路由与目标 IP 地址,寻找下一跳的地址。
当然,如果需要从两个网络命名空间访问其他公网地址,例如 google.com,需要这是 iptables 来做源地址转换,这里就不细细展开来说。