早在农历新年之前,就构思着将近半年重拾的网络基础知识整理成成一个系列,正好赶上新冠疫情在春节假期爆发,闲来无事,于是开始这一系列的笔记。
我的整体思路是:
- 第一篇笔记会简单介绍 Linux 网络数据包接收和发送过程,但不涉及 TCP/IP 协议栈的细节知识;
- 接下来总结一下常用的 Linux 虚拟网络设备,同时会结合使用 Linux 网络工具包 iproute2 来操作这些常用的网络设备;
- 有了前面的基础知识,再来看看几种常用的容器网络实现原理;
- 最后,我们将探讨一下 k8s 平台中主流的网络模型实现;
严格来说,这种学习思路其实很“急功近利”,但是,对于不太了解网络基础知识和 Linux 内核原理的同学来说,这反而是一种很有效的方式。但是,私以为学习过程不只应该由浅入深,更应该螺旋向前迭代,温故而知新,才能获益良多。
废话不多说,我们先开始第一篇笔记的内容。
数据包的接收过程
为了简化起见,我们以一个 UDP 数据包在物理网卡上处理流程来介绍 Linux 网络数据包的接收和发送过程,我会尽量忽略一些不相关的细节。
从网卡到内存
我们知道,每个网络设备(网卡)有驱动才能工作,驱动在内核启动时需要加载到内核中。事实上,从逻辑上看,驱动是负责衔接网络设备和内核网络栈的中间模块,每当网络设备接收到新的数据包时,就会触发中断,而对应的中断处理程序正是加载到内核中的驱动程序。
下面这张图详细地展示了数据包如何从网络设备进入内存,并被处于内核中的驱动程序和网络栈处理的:
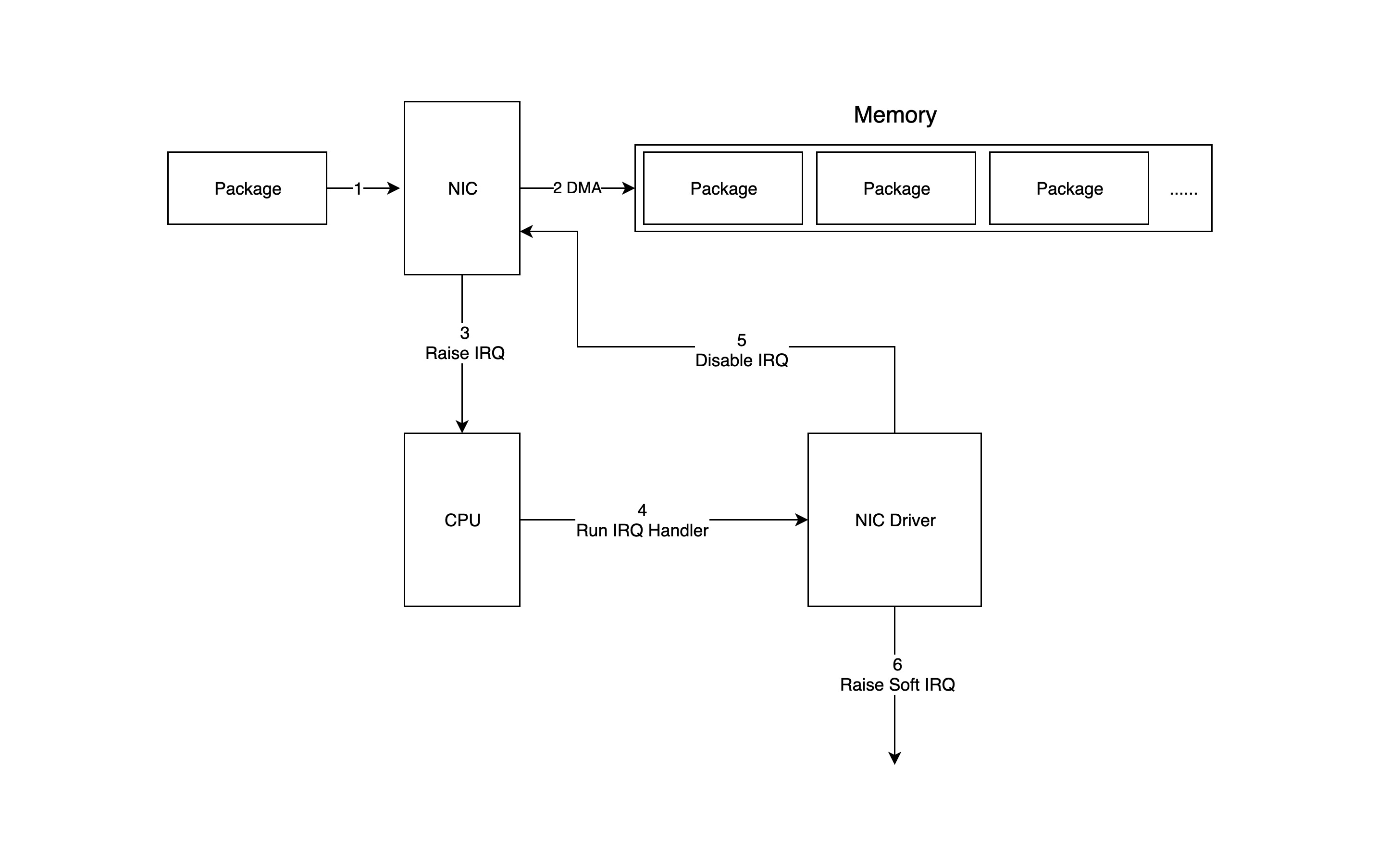
- 数据包进入物理网卡,如果目的地址不是该网络设备,且该网络设备没有开启混杂模式,该包会被该网络设备丢弃;
- 物理网卡将数据包通过 DMA 的方式写入到指定的内存地址,该地址由网卡驱动分配并初始化;
- 物理网卡通过硬件中断(IRQ)通知 CPU,有新的数据包到达物理网卡需要处理;
- 接下来 CPU 根据中断表,调用已经注册了的中断函数,这个中断函数会调到驱动程序(NIC Driver)中相应的函数;
- 驱动先禁用网卡的中断,表示驱动程序已经知道内存中有数据了,告诉物理网卡下次再收到数据包直接写内存就可以了,不要再通知 CPU 了,这样可以提高效率,避免 CPU 不停地被中断;
- 启动软中断继续处理数据包。这样做的原因是硬中断处理程序执行的过程中不能被中断,所以如果它执行时间过长,会导致 CPU 没法响应其它硬件的中断,于是内核引入软中断,这样可以将硬中断处理函数中耗时的部分移到软中断处理函数里面来慢慢处理;
内核处理数据包
上一步中网络设备驱动程序会通过触发内核网络模块中的软中断处理函数,内核处理数据包的流程如下图所示:
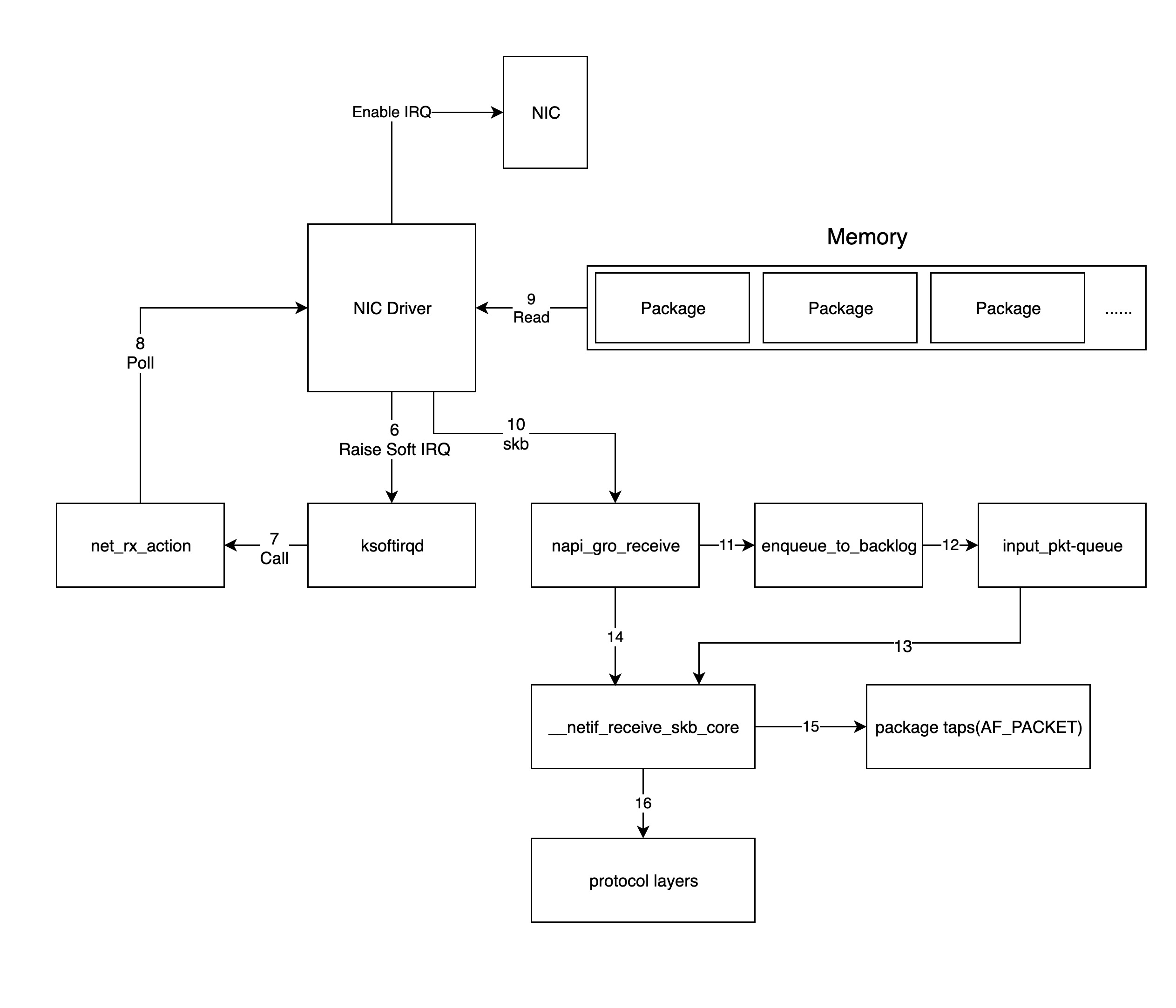
- 对上一步中驱动发出的软中断,内核中的 ksoftirqd 进程会调用网络模块的相应软中断所对应的处理函数,确切地说,这里其实是调用
net_rx_action函数; - 接下来
net_rx_action调用网卡驱动里的poll函数来一个个地处理数据包; - 而
poll函数会让驱动程序读取网卡写到内存中的数据包,事实上,内存中数据包的格式只有驱动知道; - 驱动程序将内存中的数据包转换成内核网络模块能识别的 skb(socket buffer) 格式,然后调用
napi_gro_receive函数; napi_gro_receive函数会处理 GRO 相关的内容,也就是将可以合并的数据包进行合并,这样就只需要调用一次协议栈,然后判断是否开启了 RPS;如果开启了,将会调用enqueue_to_backlog函数;enqueue_to_backlog函数会将数据包放入input_pkt_queue结构体中,然后返回;
Note: 如果
input_pkt_queue满了的话,该数据包将会被丢弃,这个队列的大小可以通过net.core.netdev_max_backlog来配置;
- 接下来 CPU 会在软中断上下文中处理自己
input_pkt_queue里的网络数据,实际上是调用__netif_receive_skb_core函数来处理; - 如果没开启 RPS,
napi_gro_receive函数会直接调用__netif_receive_skb_core函数来处理网络数据包; - 紧接着 CPU 会根据是不是有 AF_PACKET 类型的 socket(原始套接字),如果有的话,拷贝一份数据给它(tcpdump 所抓的包就是这个包);
- 将数据包交给内核 TCP/IP 协议栈处理;
- 当内存中的所有数据包被处理完成后(
poll函数执行完成),重新启用网卡的硬中断,这样下次网卡再收到数据的时候就会通知 CPU
内核网络协议栈
内核 TCP/IP 协议栈此时接收到的数据包其实是三层(网络层)数据包,因此,数据包首先会首先进入到 IP 网络层,然后进入传输层处理。
IP 网络层
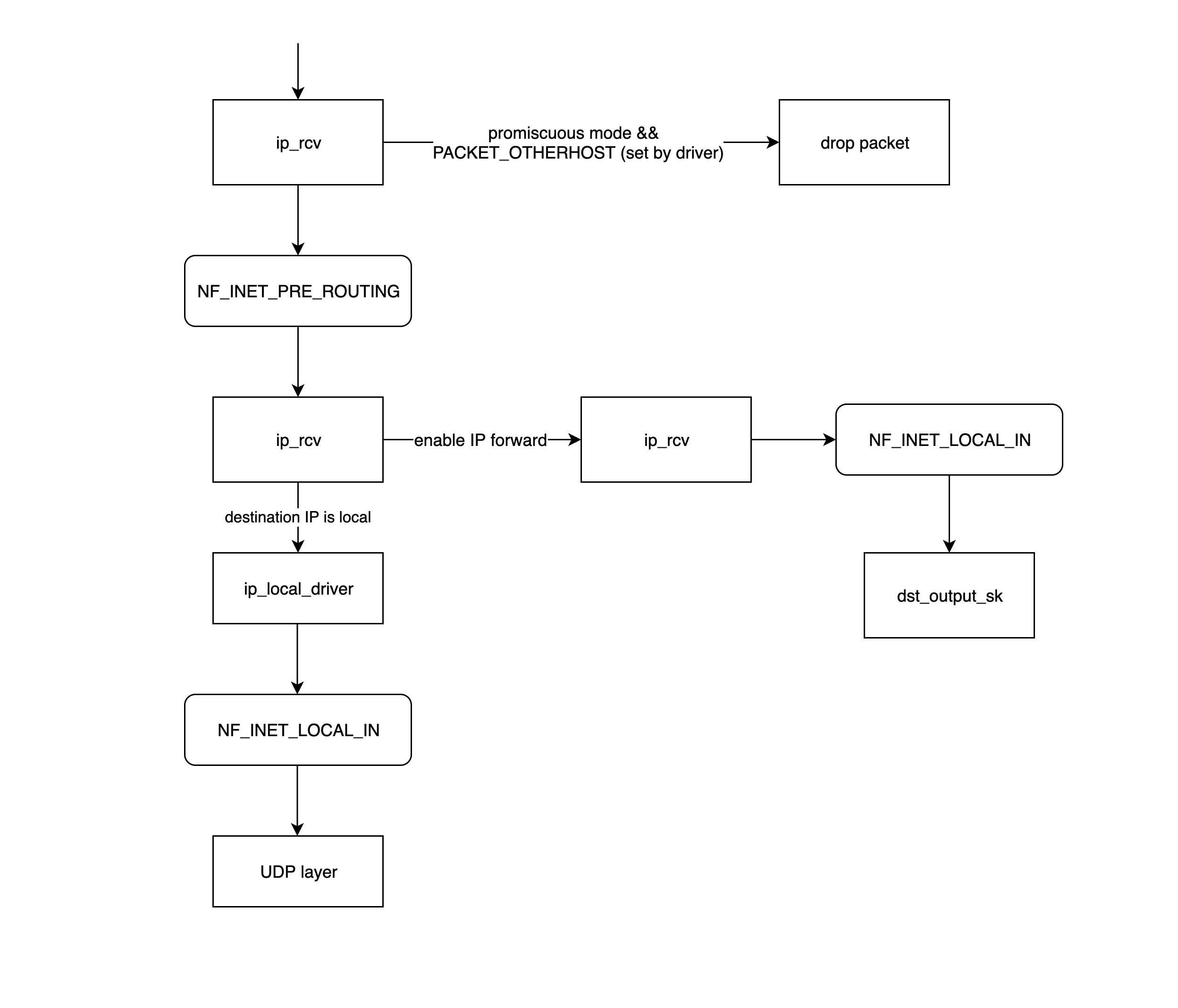
ip_rcv是函数是 IP 网络层处理模块的入口函数,该函数首先判断属否需要丢弃该数据包(目的 mac 地址不是当前网卡,并且网卡设置了混杂模式),如果需要进一步处理就调用注册在 netfilter 中的 NF_INET_PRE_ROUTING 这条链上的处理函数;- NF_INET_PRE_ROUTING 是 netfilter 放在协议栈中的钩子函数,可以通过 iptables 来注入一些数据包处理函数,用来修改或者丢弃数据包,如果数据包没被丢弃,将继续往下走;
NF_INET_PRE_ROUTING 等 netfilter 链上的处理逻辑可以通过 iptables 来设置,详情请移步至从零开始认识 iptables
- routing 进行路由处理,如果目的 IP 不是本地 IP,且没有开启 ip 转发功能,那么数据包将被丢弃;否则进入
ip_forward函数处理; ip_forward函数会先调用 netfilter 注册在 NF_INET_FORWARD 链上的处理函数,如果数据包没有被丢弃,那么将继续往后调用dst_output_sk函数;dst_output_sk函数会调用 IP 网络层的相应函数将该数据包发送出去,这一步的具体步骤将会在下一章节发送数据包中详细介绍;ip_local_deliver如果上面路由处理发现发现目的 IP 是本地 IP,那么将会调用ip_local_deliver函数,该函数先调用 NF_INET_LOCAL_IN 链上的相关处理函数,如果通过,数据包将会向下发送到传输层;
传输层
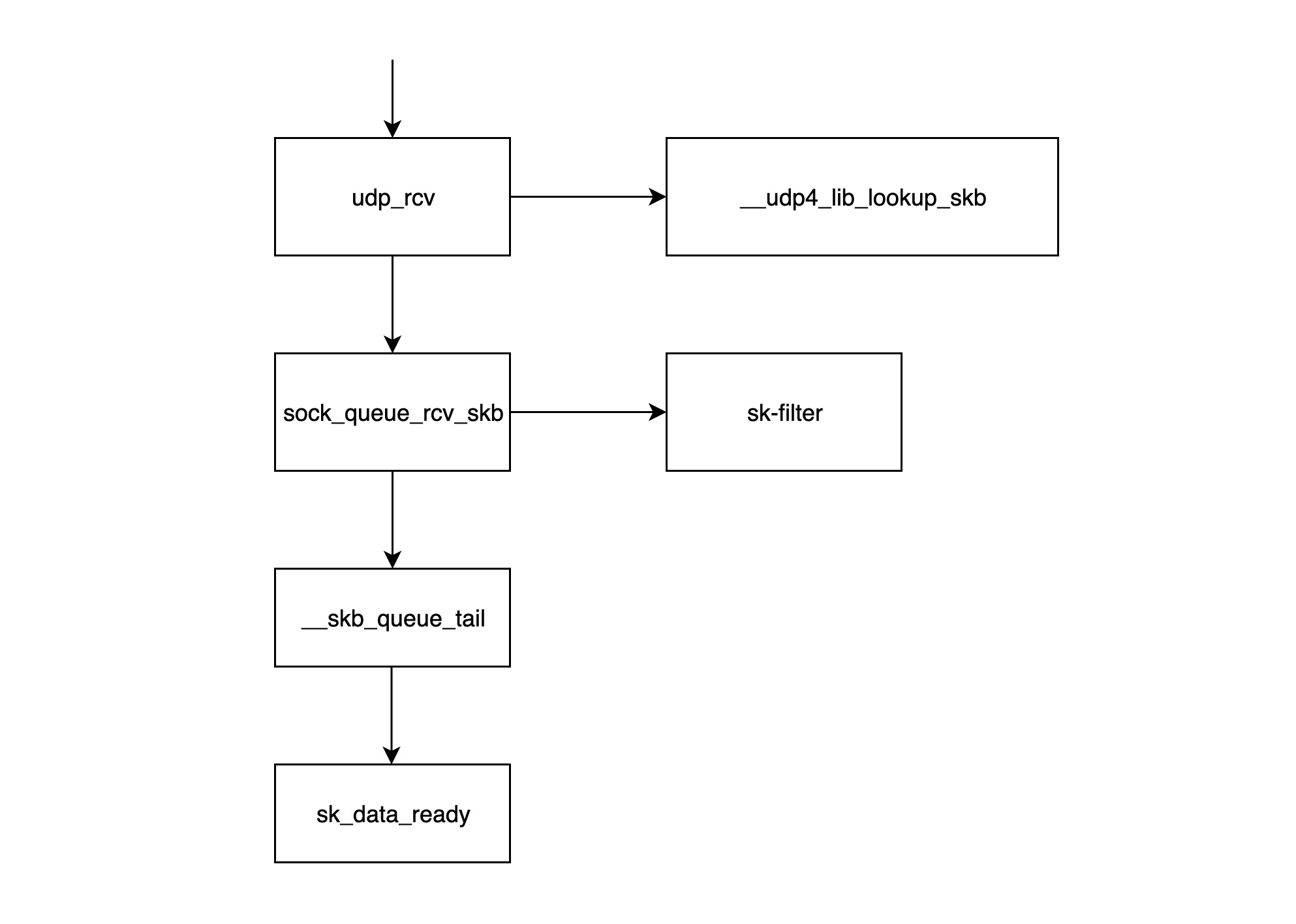
udp_rcv函数是 UDP 处理层模块的入口函数,它首先调用__udp4_lib_lookup_skb函数,根据目的 IP 和端口查找对应的 socket(所谓 socket 基本就是 ip+port 组成的结构体),如果没有找到相应的 socket,那么该数据包将会被丢弃,否则继续;sock_queue_rcv_skb该函数的职责一是检查 socket 的接收缓存是不是满了,如果满了的话就丢弃该数据包;二是调用sk_filter检查这个数据包是否是满足条件的包,如果当前 socket 上设置了 filter,且该包不满足条件的话,这个数据包也将被丢弃;__skb_queue_tail函数将数据包放入 socket 接收队列的末尾;sk_data_ready通知 socket 数据包已经准备好;- 调用完
sk_data_ready之后,一个数据包处理完成,等待应用层程序来读取;
Note: 上面所述的所有执行过程都在软中断上下文中执行。
数据包的发送过程
从逻辑上看,Linux 网络数据包的发送过程和接收过程正好相反,我们仍旧以一个 UDP 数据包通过物理网卡发送的过程为例来讲解:
应用层
应用层处理过程的起点是应用程序调用 Linux 网络接口创建 socket,下面这张图详细地展示了应用层如何构建 socket 并发送给传输层:
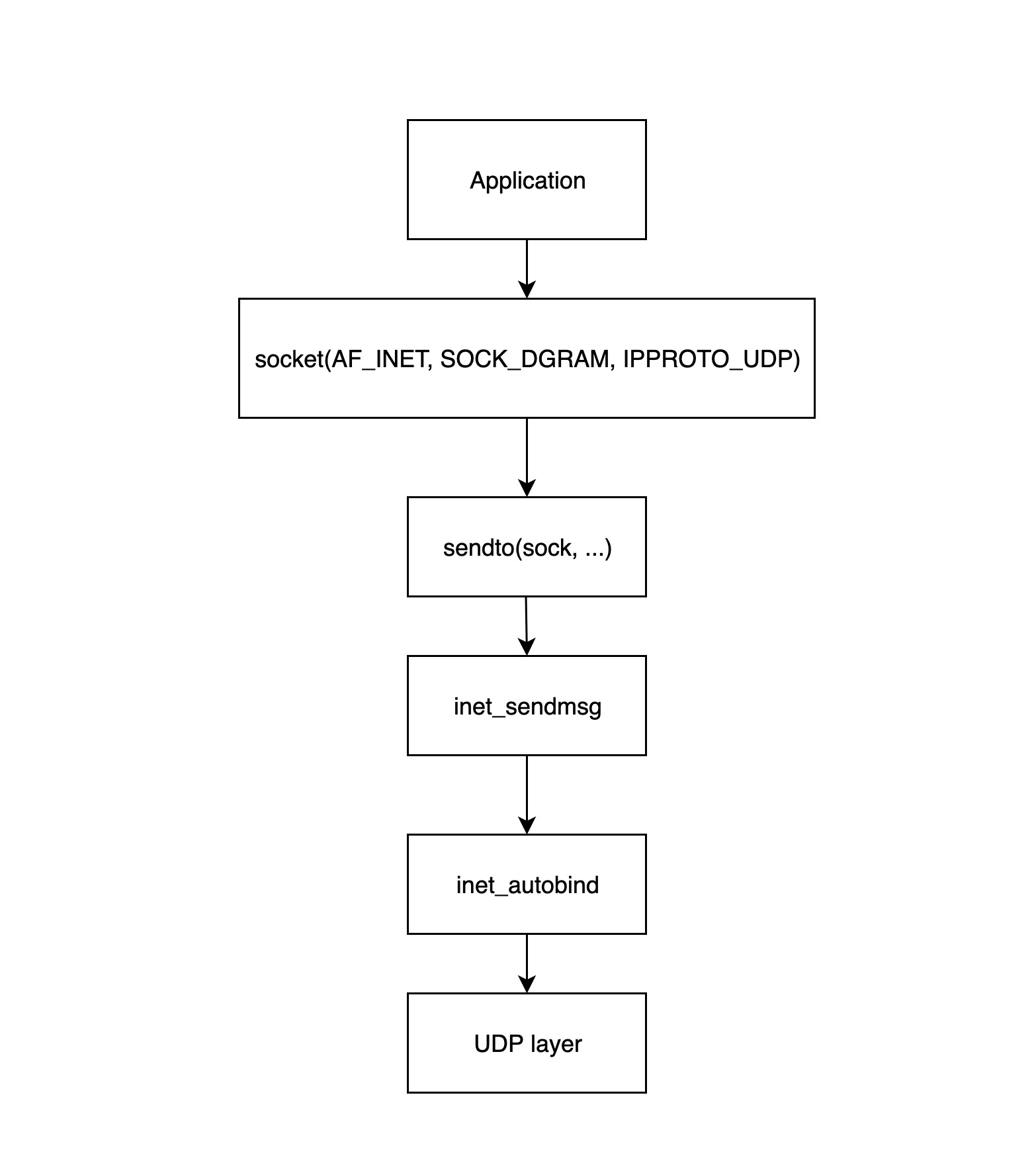
socket(...)调用该函数来创建一个 socket 结构体,并初始化相应的操作函数;sendto(sock, ...)应用层程序调用该函数开始发送数据包,该函数会调用后面的inet_sendmsg函数;inet_sendmsg该函数主要是检查当前 socket 有没有绑定源端口,如果没有的话,调用inet_autobind函数分配一个,然后调用 UDP 层的函数进行传输;inet_autobind函数会调用get_port函数获取一个可用的端口;
传输层
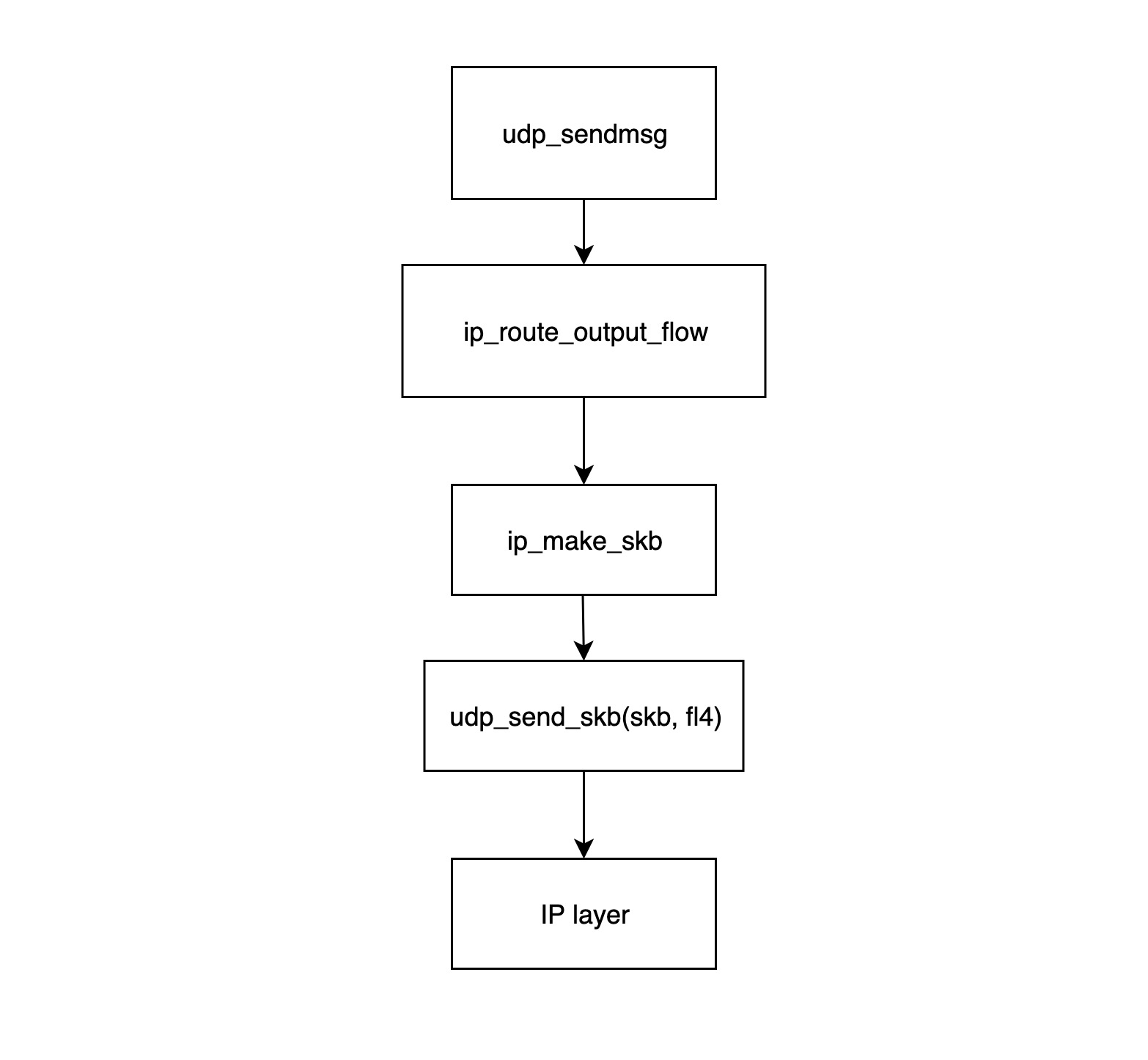
udp_sendmsg函数是 UDP 传输层模块发送数据包的入口。该函数中先调用ip_route_output_flow函数获取路由信息(主要包括源 IP 和网卡),然后调用ip_make_skb构造 skb 结构体,最后将网卡信息和该 skb 关联起来;ip_route_output_flow函数主要处理路由信息,它会根据路由表和目的 IP,找到这个数据包应该从哪个网络设备发送出去,如果该 socket 没有绑定源 IP,该函数还会根据路由表找到一个最合适的源 IP 给它。 如果该 socket 已经绑定了源 IP,但根据路由表,从这个源 IP 对应的网卡没法到达目的地址,则该包会被丢弃,于是数据发送失败将返回错误。该函数最后会将找到的网络设备和源 IP 塞进flowi4结构体并返回给udp_sendmsg函数;ip_make_skb函数的功能是构造 skb 包,构造好的 skb 包里面已经分配了 IP 包头(包括源 IP 信息),同时该函数会调用__ip_append_dat函数对数据包进行分片,同时还会在该函数中检查 socket 的发送缓存是否已经用光,如果被用光的话,返回ENOBUFS错误信息;udp_send_skb(skb, fl4)函数主要是往 skb 里面填充 UDP 的包头,同时处理校验值,然后交给 IP 网络层的相应函数处理;
IP 网络层
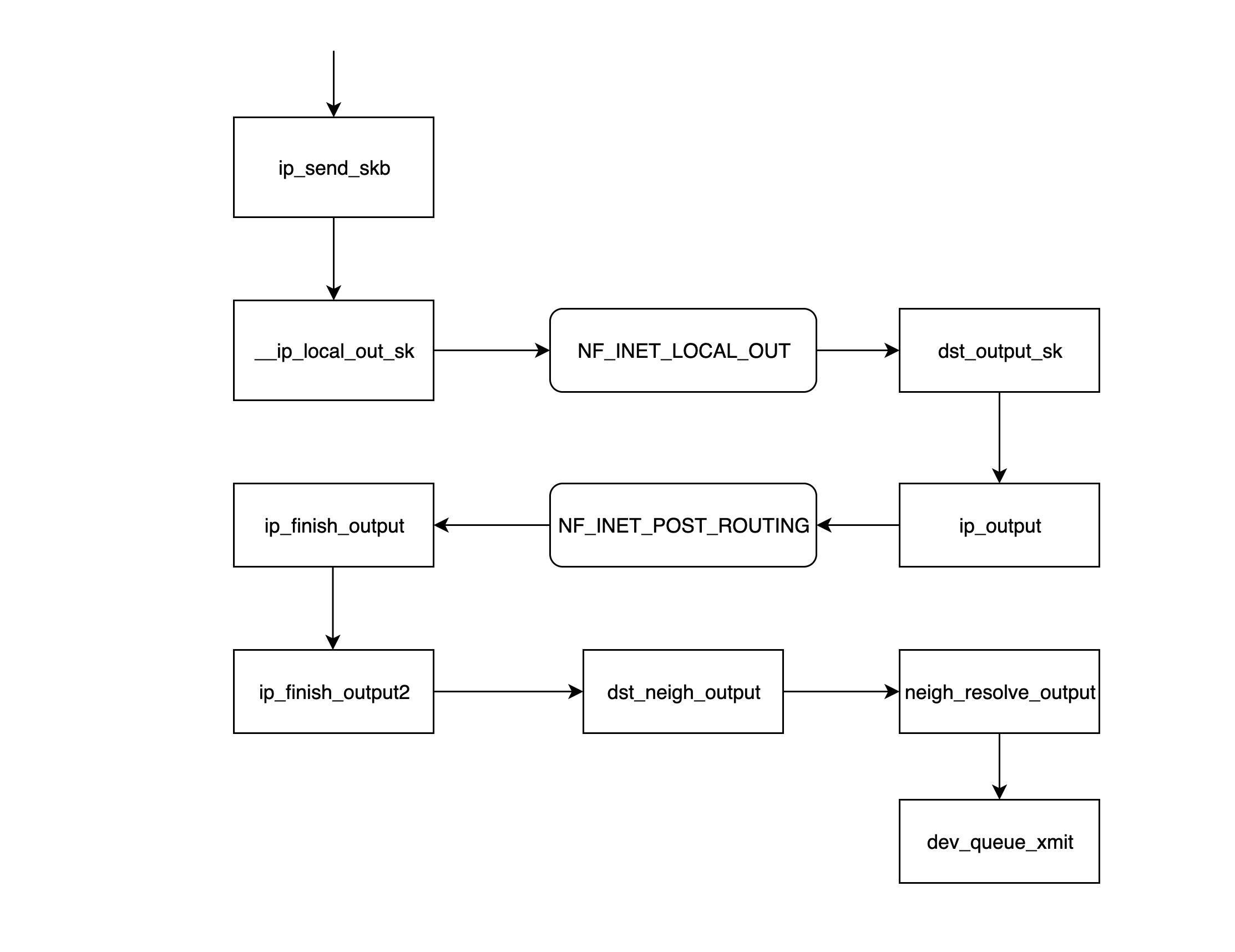
ip_send_skb是 IP 网络层模块发送数据包的入口函数,该函数主要是调用后面的一系列的函数来发送网络层数据包;__ip_local_out_sk函数用来设置 IP 报文头的长度和校验值,然后调用下面 netfilter 钩子链 NF_INET_LOCAL_OUT 上注册的处理函数;- NF_INET_LOCAL_OUT 是 netfilter 钩子关卡,可以通过 iptables 来配置链上的处理函数;如果该数据包没被丢弃,则继续往下走;
dst_output_sk该函数根据 skb 里面的信息,调用相应的 output 函数ip_output;ip_output函数将上一层udp_sendmsg得到的网卡信息写入 skb 然后调用 netfilter 钩子链 NF_INET_POST_ROUTING 上注册的处理函数;- NF_INET_POST_ROUTING 是 netfilter 钩子关卡,可以通过 iptables 来配置链上的处理函数;在这一步主要是配置了原地址转换(SNAT),从而导致该 skb 的路由信息发生变化;
ip_finish_output函数判断经过了上一步的处理之后路由信息是否发生变化,如果发生变化的话,需要重新调用dst_output_sk函数(重新调用这个函数时,可能就不会再走到ip_output函数调用的分支,而是走到被 netfilter 指定的 output 函数,这里有可能是 xfrm4_transport_output),否则接着往下走;ip_finish_output2函数根据目的 IP 到路由表里面找到下一跳(nexthop)的地址,然后调用__ipv4_neigh_lookup_noref函数去 arp 表里面找下一跳的 neigh 信息,没找到的话会调用__neigh_create函数构造一个空的 neigh 结构体;dst_neigh_output函数调用neigh_resolve_output函数获取 neigh 信息,并将信息里面的 mac 地址填到 skb 中,然后调用dev_queue_xmit函数发送数据包;
内核处理数据包
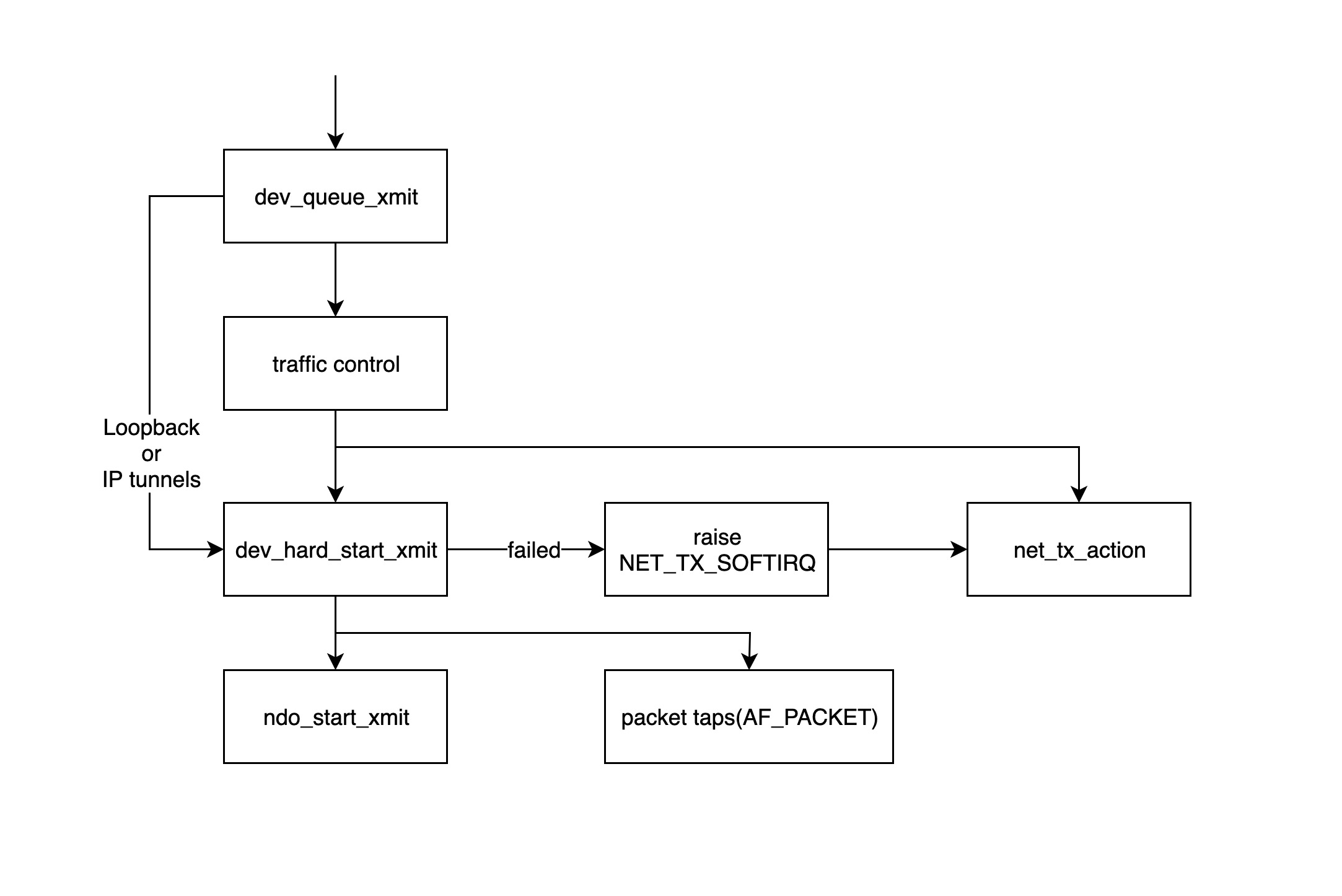
dev_queue_xmit函数是内核模块开始处理发送数据包的入口,该函数会先获取设备对应的 qdisc,如果没有的话(如 loopback 或者 IP tunnels),就直接调用dev_hard_start_xmit函数,否则数据包将经过 traffic control 模块进行处理;- traffic control 模块主要对数据包进行过滤和排序,如果队列满了的话,数据包会被丢掉,详情请参考: http://tldp.org/HOWTO/Traffic-Control-HOWTO/intro.html
dev_hard_start_xmit函数先拷贝一份 skb 给“packet taps”(tcpdump 命令的数据就从来自于此),然后调用ndo_start_xmit函数来发送数据包。如果dev_hard_start_xmit函数返回错误的话,调用它的函数会把 skb 放到一个地方,然后抛出软中断 NET_TX_SOFTIRQ 交给软中断处理程序net_tx_action函数稍后重试处理;ndo_start_xmit函数绑定到具体驱动发送数据的处理函数;
Note:
ndo_start_xmit函数会指向具体的网卡驱动发送数据包的函数,这一步之后,数据包发送任务就交给网络设备驱动程序了,不同的网络设备驱动有不同的处理方式,但是大致流程基本一致:
- 将 skb 放入网卡自己的发送队列
- 通知网卡发送数据包
- 网卡发送完成后发送中断给 CPU
- 收到中断后进行 skb 的清理工作
总结
理解了 Linux 网络数据包的接收和发送流程,我们就可以知道在哪些地方监控和修改数据包,哪些情况下数据包可能被丢弃,特别是了解了 netfilter 中相应钩子函数的位置,对于了解 iptables 的用法有一定的帮助,同时也会帮助我们更好的理解 Linux 下的网络虚拟设备。