什么是 eBPF
eBPF 全称为 Extended Berkeley Packet Filter,源于 BPF(Berkeley Packet Filter), 从其命名可以看出来,它适用于网络报文过滤的功能模块。但是,eBPF已经进化为一个通用的执行引擎,其本质为内核中一个类似于虚拟机的功能模块。eBPF 允许开发者编写在内核中运行的自定义代码,并动态加载到内核,附加到某个处罚 eBPF 程序执行的内核事件上,而不再需要重新编译新的内核模块,可以根据需要动态加载和卸载 eBPF 程序。由此开发者可以基于 eBPF 开发各种网络、可观察性以及安全方面的工具,正因为如此,才让 eBPF 在云原生盛行的当下如鱼得水。
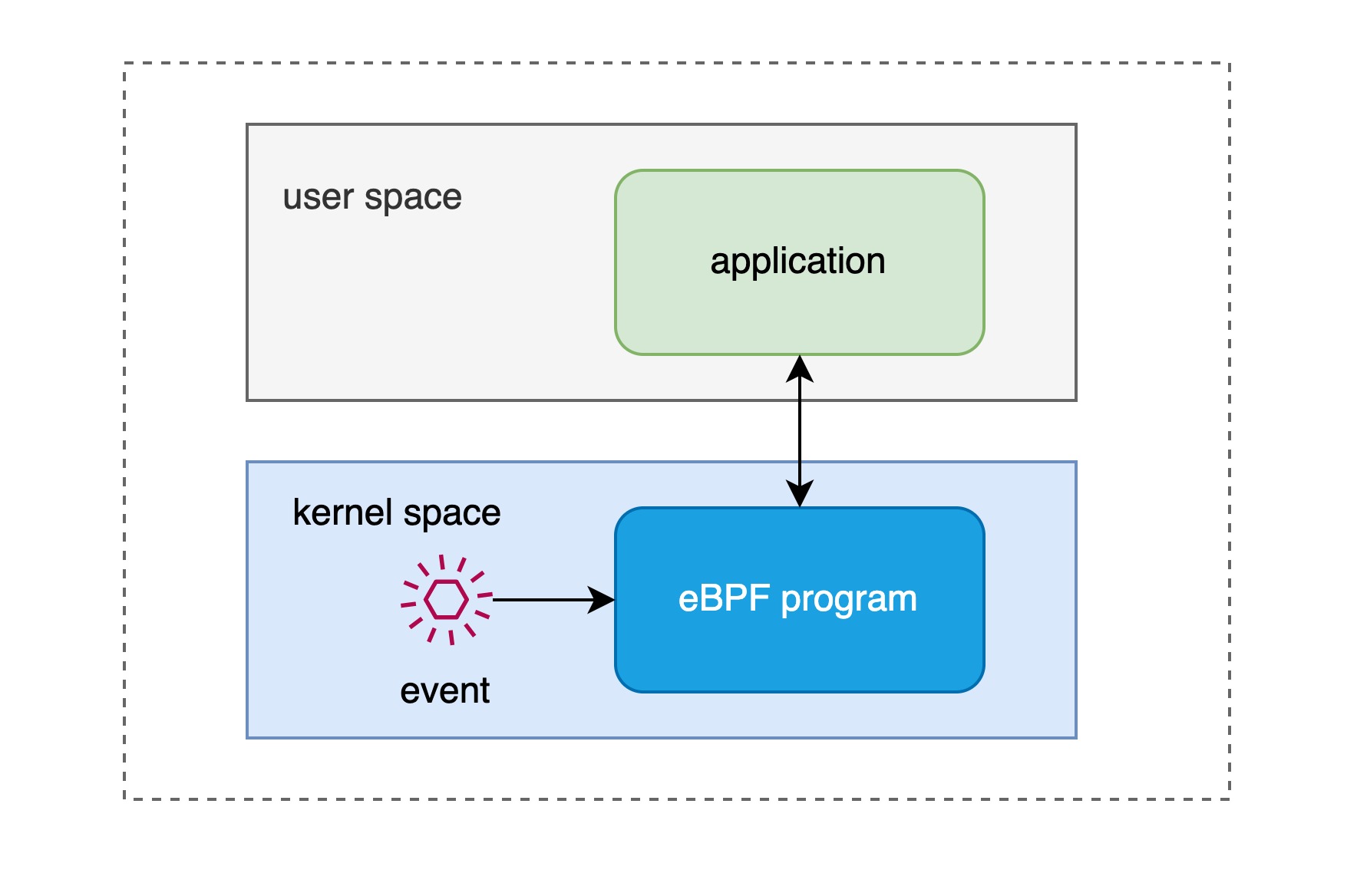
Note: 最初的 BPF 广泛使用在类 unix 的内核中,而重新设计开发的 eBPF 最早集成在 3.18 的 linux 内核中,此后 BPF 就被被称为经典 BPF,也就是 cBPF(classic BPF),如今的 linux 内核不在运行 cBPF ,内核会将加载的 cBPF 字节码透明地转换成 eBPF 再执行。
eBPF 是如何工作的
一般来说,eBPF 程序包括两部分:
- eBPF 程序本身
- 使用 eBPF 的应用程序
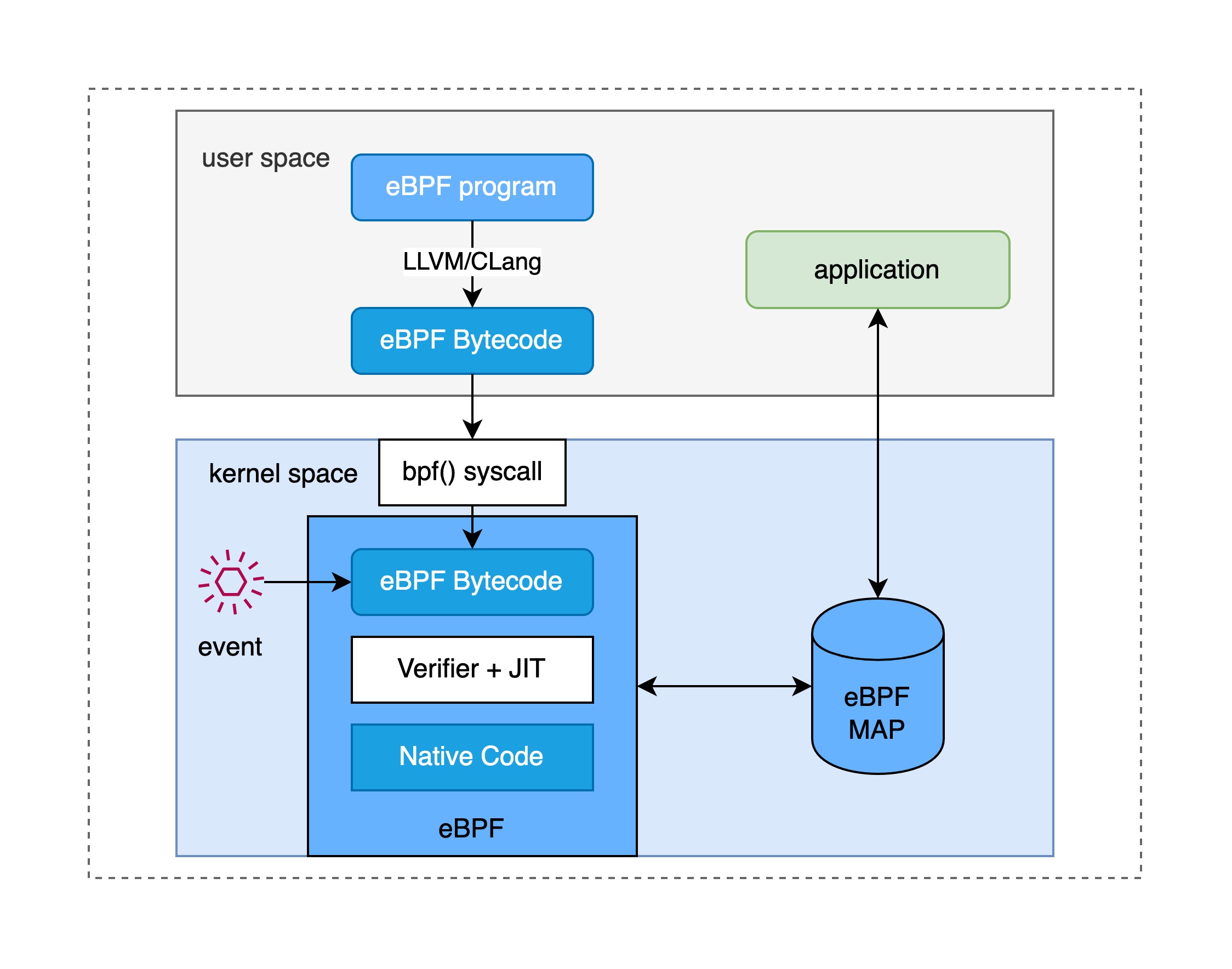
先说使用 eBPF 的应用程序,它运行在用户空间,通过系统调用来加载 eBPF 程序,将其 attach 到某个出发此 eBPF 的内核事件上。如今的内核版本已经支持将 eBPF 程序可以加载到很多类型的内核事件上,最典型的是内核收到网络数据包的事件,这也是 BPF 最初的设计初衷,网络报文的过滤。除此之外,还可以将 eBPF 程序附加到和黑函数的入口(kprobe)以及跟踪点(trace point)等上面。eBPF 的应用程序有时候也需要读取从 eBPF 程序中传回的统计信息,事件报告等。
而 eBPF 程序本身使用 C 语言编写的 “内核代码”,注入到内核之前需要用 LLVM 编译器编译得到 BPF 字节码,然后加载程序将字节码载入内核。当然,为了防止注入的 eBPF 程序导致内核崩溃,内核中有专门的验证器保证 eBPF 程序的安全性,如 eBPF 不能随意调用内核参数,只能受限于 BPF helpers 函数;除此之外,eBPF 程序不能包涵不能到达的逻辑,循环必须在有限时间内完成且次数有限制等等。
eBPF 程序和应用程序可以通过一个位于内核中的 eBPF MAP 来实现双向通信,该 MAP 常驻内存,可以将内核中的统计摘要信息回传给用户空间的应用程序。此外,eBPF MAP 还可用于 eBPF 程序与内核态程序以及 eBPF 程序之间的通信。
eBPF 实例
按照传统,我们需要编写一个 eBPF 版本的 Hello World,并让其运行起来。我们的 eBPF 程序用 C 语言编写,而 eBPF 应用程序选择使用 Golang + libbpfgo,当然你也可以选择使用 C 语言。
本文实例的运行环境信息如下:
- Ubuntu 20.04 LTS
- Kernel Version 5.15.0
- Golang 18.7
安装依赖:
sudo apt-get update
sudo apt-get install make llvm clang libbpf-dev libelf-dev
Note: 其中 llvm 与 clang 是我们用的到编译器,libbpf-dev 与 libelf-dev 包含我们编写 eBPF 程序的依赖库。
先看看 eBPF 程序本身。代码信息非常简单,程序的入口通过编译器宏 kprobe/sys_execve 指定,入口函数的参数对于不同的 eBPF 程序类型有着不同的参数,这里参数为 *ctx。核心需要关注的是头文件 <linux/bpf.h> 来自kernel的头文件,默认安装在 /usr/include/linux/bpf.h;而 <bpf/bpf_helpers.h> 包含 eBPF 的 helpers 函数,来自 libbpf, 这个需要单独安装,我们在依赖准备的时候已经都安装完成了。这段代码的核心函数调用了 bpf_trace_printk 来自于 eBPF 的 helpers 函数。最后代码声明了 SEC 宏来定义 License,因为加载进内核的 eBPF 程序需要有 License 检查。
// +build ignore
// workround for asm_inline issue: https://github.com/iovisor/bcc/commit/2d1497cde1cc9835f759a707b42dea83bee378b8
#include <linux/types.h>
#ifdef asm_inline
#undef asm_inline
#define asm_inline asm
#endif
typedef __u64 u64;
#include <linux/bpf.h>
#include <bpf/bpf_helpers.h>
// print tracing message on a kprobe
SEC("kprobe/sys_execve")
int hello(void *ctx)
{
char msg[] = "Hello eBPF!\n";
bpf_trace_printk(msg, sizeof(msg));
return 0;
}
char LICENSE[] SEC("license") = "Dual BSD/GPL";
再来看看加载 eBPF 的应用程序,我们使用 Golang 编写并且使用 libbpfgo 来加载 eBPF 程序到内核,由于这个实力非常简单,并没有涉及到使用 eBPF MAP 来和 eBPF 程序通信。加载程序运行在用户态,最终需要系统调用 bpf() 来加载 eBPF 字节码,此处使用 libbpfgo 帮我们简化这一过程,直接调用 NewModuleFromFile 创建 bpfModule 然后从中得到 hello 的 eBPF 程序并且附加早内核 kprobe。需要注意的是,一个 bpfModule 可以包含多个 eBPF 程序。
package main
import (
"C"
"os"
"os/signal"
"github.com/aquasecurity/tracee/libbpfgo"
)
import (
)
func main() {
sig := make(chan os.Signal, 1)
signal.Notify(sig, os.Interrupt)
bpfModule, err := libbpfgo.NewModuleFromFile("hello.bpf.o")
if err != nil {
panic(err)
}
defer bpfModule.Close()
err = bpfModule.BPFLoadObject()
if err != nil {
panic(err)
}
prog, err := bpfModule.GetProgram("hello")
if err != nil {
panic(err)
}
_, err = prog.AttachKprobe(sys_execve)
if err != nil {
panic(err)
}
go libbpfgo.TracePrint()
<-sig
}
接下来,我们看看如何编译并运行 eBPF 程序。在这个简单的例子中我们先构建对象文件,然后构建用户空间的应用程序,由它来加载 eBPF 字节码到内核,并在用户空间运行应用程序。
ARCH=$(shell uname -m)
TARGET := hello
TARGET_BPF := $(TARGET).bpf.o
GO_SRC := *.go
BPF_SRC := *.bpf.c
LIBBPF_HEADERS := /usr/include/bpf
LIBBPF_OBJ := /usr/lib/$(ARCH)-linux-gnu/libbpf.a
.PHONY: all
all: $(TARGET) $(TARGET_BPF)
go_env := CC=clang CGO_CFLAGS="-I $(LIBBPF_HEADERS)" CGO_LDFLAGS="$(LIBBPF_OBJ)"
$(TARGET): $(GO_SRC)
$(go_env) go build -o $(TARGET)
$(TARGET_BPF): $(BPF_SRC)
clang \
-I /usr/include/$(ARCH)-linux-gnu \
-O2 -c -target bpf \
-o $@ $<
有了 makefile, 我们知足要执行 make all 就可以构建我们需要的可执行应用程序和作为目标文件的 eBPF 字节码。然后运行应用程序(以特权身份运行或者拥有 CAP_BPF ),应该看到类似于下面的代码输出:
# make all
# ./hello
amazon-ssm-agen-36390 [003] d...1 83327.936931: bpf_trace_printk: Hello eBPF!
amazon-ssm-agen-36391 [001] d...1 83388.944212: bpf_trace_printk: Hello eBPF!
cron-36394 [002] d...1 83443.496894: bpf_trace_printk: Hello eBPF!
bash-36395 [003] d...1 83443.497557: bpf_trace_printk: Hello eBPF!
...
如果此时,我们在另外一个终端运行 bash,其进程 ID 为 36395,那么上面的输出中可以看到 bash-36395 的进程调用,这也说明了这个简单的 eBPF 版本的 Hello World 可以看到所有这些不同的进程调用的执行,这也就是 eBPF 的强大功能,内核中的 eBPF 程序知道此机器上的所有进程活动信息并传回给用户空间的应用程序。
eBPF 与 Kubernetes
eBPF 让内核可编程,使得其在云原生领域大放异彩,特别是在 Kubernetes 宇宙中。试想一下,Kubernetes 中的容器或者pod运行于 node 所在的物理机或者虚拟机上面,它们主要运行在用户空间,共享同一个内核;而我们现在可以在 node 的内核中注入开发者的 eBPF 程序,这意味着我们可以在通过 eBPF 知道所有容器或者pod中应用程序的有关信息,包括但不局限于应用程序的发送/接收的网络流量、读写文件,也可以为新创建的 pod 分配 IP等等。实际上,已经有很多基于 eBPF 开发的成熟监控、网络管理已经安全检测的组件,最有名的莫过于 Cilium.
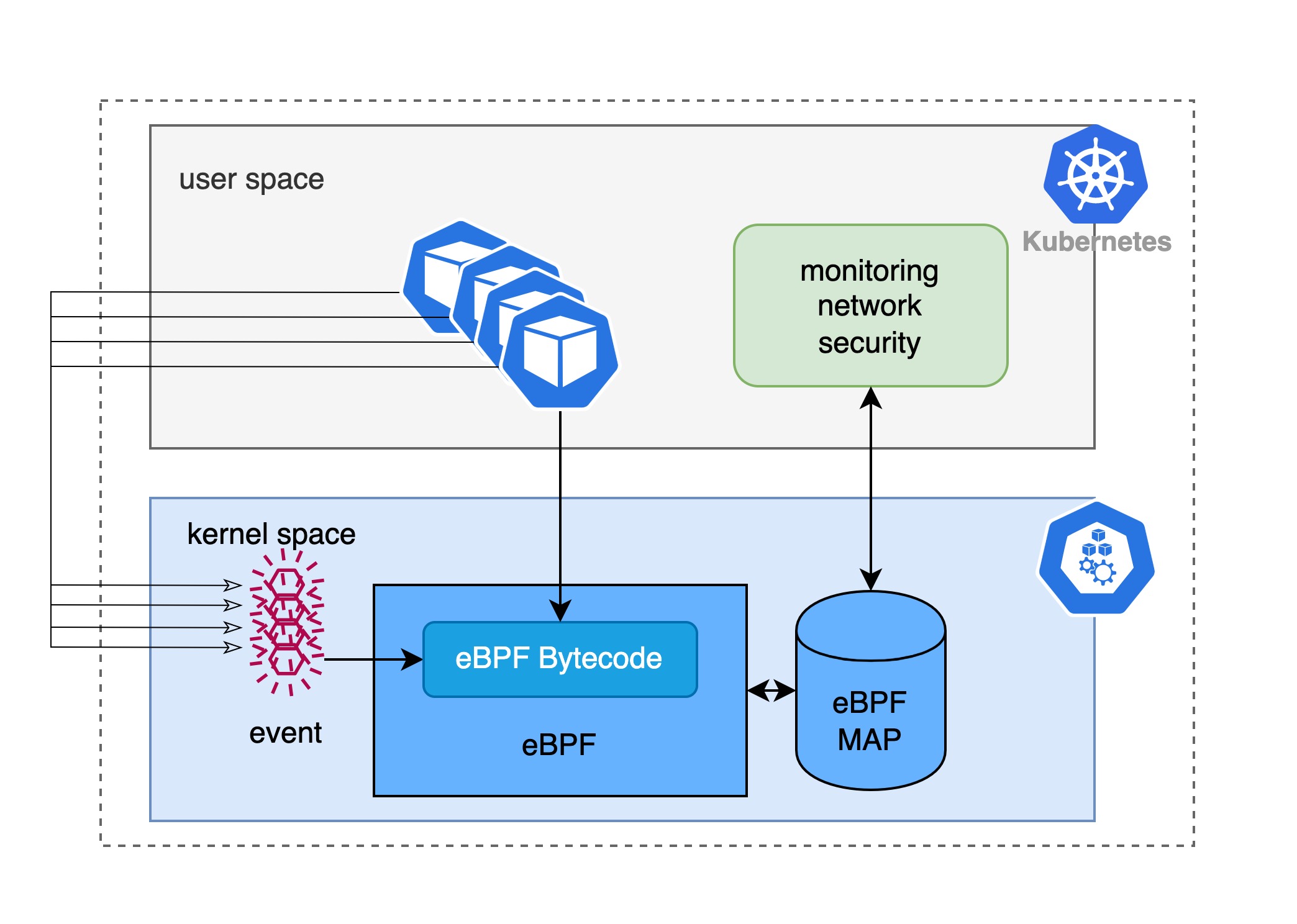
另外,在 kubernetes 宇宙中,很多组建使用 Sidecar 的模式通过诸如 sidecar 来实现可观察性、流量管理以及安全策略实施等,最典型的莫过于 Istio 使用 istio sidecar 接管 pod 的网络流量来实现构建服务网格。这种模型充分利用 pod 内容器共享相同的网络命名空间以及挂载卷等内容,所以通过注入(手动注入或者通过admission webhook自动注入)sidecar 来获取目标 pod 的活动信息。sidecar 模式的问题在于一旦 sidecar 会带来额外的性能开销,而且一旦sidecar配置正确,可能会导致功能无法正常工作甚至影响应用程序本身的运行,所以,sidecar 模式很难真正地实现副用户完全透明。而 eBPF 的好处在于应用程序的部署不需要做任何更改,就可以知道所有的容器或者 pod 中发生的所有事情,这就是 eBPF 这种内核可编程技术令人兴奋的原因之一,使用 eBPF 来实现可观察性、网络管理以及安全策略实施工具。
总结
eBPF 是一项提高内核中的可观测性、网络和安全性的新技术。它让内核无需更改就可以实现更复杂的功能,由此让开发者可以更加简单且灵活地创建更丰富的工具来支持基础系统设施的运行。我们已经大概知道了 eBPF 是什么、它是如何工作的、以及为什么它在 Kubernetes 宇宙中潜力无穷。当然 eBPF 完美无缺,编写 eBPF 代码不是一件容易的事,而且 eBPF 程序有很多限制,它并不是一个图灵完备的,希望随着内核版本的更迭,eBPF 生态系统也愈加成熟。最后也不得不提到另外一个目前在云原生领域比较流行的虚拟机技术 - WebAssembly,它运行在用户空间,却可以处理很多类内核的工作,以至于 CNCF 基于 LLVM 开发了云原生的 WebAssembly 运行时 WasmEdge Runtime,这样,原生应用程序将所有沙箱检查合并到原生库中,这允许 WebAssembly 程序表现得像一个独立的 unikernel 库操作系统。