话说自己入坑云原生也有好几年了,但是对 kubernetes 基础认识却不够深,导致写代码的时候经常需要打开 godoc 或者 kubernetes 源码查看某个接口或者方法的定义。这种快餐式的消费代码方式可以解决常见的问题,但有时候却会被一个简单的问题困扰很久。究其原因,还是没有对 kubernetes 有比较系统的学习,特别对于 kubernetes API 的设计与原理没有较为深入的认识,这也是我们平时扩展 kubernetes 功能绕不开的话题。与此同时,这也是很难讲清楚的一个话题,是因为 kubernetes 经过多个版本的迭代功能已经趋于成熟与复杂,这一点也可以从 Github 平台 kubernetes 组织下的多个仓库也可以看得出来,相信很多人和我一样,看到 kubernetes、client-go、api、apimachinery 等仓库就不知道如何下手。事实上,从 API 入手是比较简单的做法,特别是我们对于 kubernetes 核心组件的功能有了一定的了解之后。
接下来的几篇笔记,我将由浅入深地学习 kubernetes API 的设计以及背后的原理。我的计划是这样的:
- 初识 kubernetes API 的组织结构
- 深入 kubernetes API 的源码实现
- 扩展 kubernetes API 的典型方式
废话不多说,我们先来认识一下 kubernetes API 的基础结构以及背后的设计原理。
API-Server
我们知道 kubernetes 控制层面的核心组件包括 API-Server、 Controller Manager、Scheduler,其中 API-Server 对内与分布式存储系统 etcd 交互实现 kubernetes 资源(例如 pod、namespace、configMap、service 等)的持久化,对外提供通过 RESTFul 的形式提供 kubernetes API 的访问接口,除此之外,它还负责 API 请求的认证(authN)、授权(authZ)以及验证。刚提到的“对外”是相对的概念,因为除了像 kubectl 之类的命令行工具之外,kubernetes 的其他组件也会通过各种客户端库来访问 kubernetes API,关于官方提供的各种客户端库请查看 client-libraries 列表,其中最典型的是 Go 语言的客户端库 client-go。
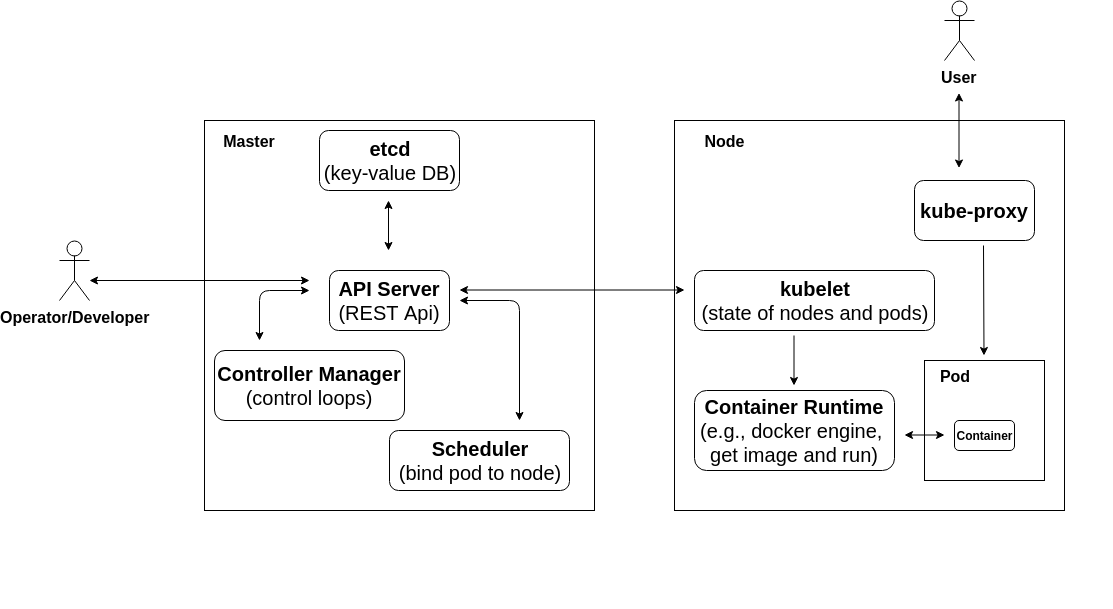
API-Server 是 kubernetes 控制层面中唯一一个与 etcd 交互的组件,kubernetes 的其他组件都要通过 API-Server 来更新集群的状态,所以说 API-Server 是无状态的;当然也可以创建多个API-Server 的实例来实现容灾。API-Server 通过配合 controller 模式来实现声明式的 API 管理 kubernetes 资源。
既然我们知道了 API-Server 的主要职责是提供 kubernetes 资源的 RESTFul API,那么客户端怎么去请求 kubernetes 资源, API-Server 怎么去组织这些 kubernetes 资源呢?
GVK vs GVR
Kubernetes API 通过 HTTP 协议以 RESTful 的形式提供,API 资源的序列化方式主要是以 JSON 格式进行,但为了内部通信也支持 Protocol Buffer 格式。为了方便扩展与演进,kubernetes API 支持分组与多版本,这体现在不同的 API 访问路径上。有了分组与多版本支持,即使要在新版本中去掉 API 资源的特定字段或者重构 API 资源的展现形式,也可以保证版本之间的兼容性。
API-group
将整个 kubernetes API 资源分成各个组,可以带来很多好处:
- 各组可以单独打开或者关闭
- 各组可以有独立的版本,在不影响其他组的情况下单独向前衍化
- 同一个资源可以同时存在于多个不同组中,这样就可以同时支持某个特定资源稳定版本与实验版本
关于 kubernetes API 资源的分组信息可以在序列化的资源定义中有所体现,例如:
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-deploy
spec:
...
其中 apiVersion 字段中 apps 即为 Deployment 资源的分组,实际上,Deployment 不止出现在 apps 分组里,也出现在 extensions 分组中,不同的分组可以实验不同的特性;另外,kubernetes 中的核心资源如 pod、namespace、configmap、node、service 等存在于 core 分组中,但是由于历史的原因,core 不出现在 apiVersion 字段中,例如以下定义一个 pod 资源的序列化对象:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
labels:
app: exp
...
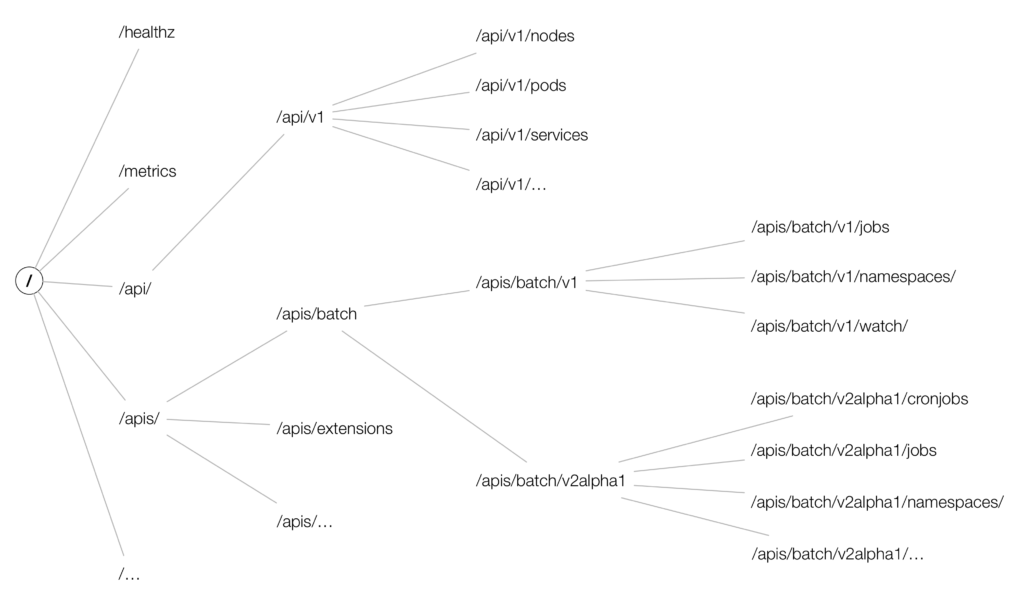
API 分组也体现在访问资源的 RESTful API 路径上,core 组中的资源访问路径一般为 /api/$VERSION,其他命名组的资源访问路径则是 /apis/$GROUP_NAME/$VERSION,此外还有一些系统级别的资源,如集群指标信息 /metrics,以上这些就基本构成了 kubernetes API 的树结构:
API-version
为了支持独立的演进,kubernetes API 也支持不同的版本,不同的版本代表不同的成熟度。注意,这里说的是 API 而非资源支持多版本。因为多版本支持是针对 API 级别,而不是特定的资源或者资源的字段。一般来说,我们根据 API 分组、资源类型、namespace 以及 name 来区分不同的资源对象,对于同一个资源对象的不同版本,API-Server 负责不同版本之间的无损切换,这点对于客户端来说是完全透明的。事实上,不同版本的同类型的资源在持久化层的数据可能是相同的。例如,对于同一种资源类型支持 v1 和 v1beta1 两个 API 版本,以 v1beta1 版本创建该资源的对象,后续可以以v1 或者 v1beta1 来更新或者删除该资源对象。
API 多版本支持一般通过将资源分组置于不同的版本中来实现,例如,batch 同时存在 v2alph1 与 v1 版本。一般来说,新的资源分组先出现 v1alpha1 版本,随着稳定性的提高被推进到 v1beta1 ,最后从 v1 版本毕业。
随着新的用户场景出现,kubernetes API 需要不断变化,可能是新增一个字段,也可能是删除旧的字段,甚至是改变资源的展现形式。为了保证兼容性,kubernetes 制定了一系列的策略。总的来说,对于已经 GA 的 API,Kubernetes 严格维护其兼容性,终端用户可以放心食用,beta 版本的 API 则尽量维护,保证不打破版本跨版本之间的交互,而对于 alpha 版本的 API 则很难保证兼容性,不太推荐生产环境使用。
GVK 与 GVR 映射
在 kubernetes API 宇宙中,我们经常使用 GVK 或者 GVR 来区分特定的 kubernetes 资源。其中 GVK 是 Group Version Kind 的简称,而 GVR 则是 Group Version Resource 的简称。
通过上面对于 kubernetes API 分组和多版本的介绍,我们已经了解了 Group 与 Version,那么 Kind 与 Resource 又分别是指什么呢?
Kind 是 API “顶级”资源对象的类型,每个资源对象都需要 Kind 来区分它自身代表的资源类型,例如,对于一个 pod 的例子:
apiVersion: v1
kind: Pod
metadata:
name: example-pod
labels:
app: exp
...
其中 kind 字段即代表该资源对象的类型。一般来说,在 kubernetes API 中有三种不同类型的 Kind:
- 单个资源对象的类型,最典型的就是刚才例子中提到的 Pod
- 资源对象的列表类型,例如 PodList 以及 NodeList 等
- 特殊类型以及非持久化操作的类型,很多这种类型的资源是 subresource, 例如用于绑定资源的
/binding、更新资源状态的/status以及读写资源实例数量的/scale
需要注意的是,同一个 Kind 的资源类型不止可以出现在同一分组的不同版本中,如 apps/v1beta1 与 apps/v1,它还可能出现在不同的分组中,例如 Deployment 开始以 alpha 特性出现在 extensions 分组,GA 之后被推进到 apps 组,所以为了严格区分不同的 Kind,需要组合 API 的 Group、Version 与 Kind 形成 GVK。
Resource 则是用来以 HTTP 协议将 JSON 格式发送或者读取的资源展现形式,可以通过单个资源对象展现,例如 .../namespaces/default,也可以通过资源列表的形式展现,例如 .../jobs。要正确的请求资源对象,API-Server 必须知道 apiVersion 与请求的资源,这样 API-Server 才能正确地解码请求信息,这些信息正是处于请求的资源路径中。一般来说,把 API 对象的 Group、Version 以及 Resource 组合成为 GVR 并形成特定的资源请求路径,就可以区分请求的特定资源,例如 /apis/batch/v1/jobs 就是请求所有的 jobs 信息。
GVR 常用于组合成 RESTful API 请求路径。例如,针对 apps/v1 下面 Deployment 的 RESTful API 请求路径如下所示:
GET /apis/apps/v1/namespaces/{namespace}/deployments/{name}
通过获取资源的 JSON 或 YAML 格式的序列化对象,进而从资源的类型信息中可以获得该资源的 GVK;相反,通过 GVK 信息则可以获取要读取的资源对象的 GVR,进而构建 RESTful API 请求获取对应的资源。这种 GVK 与 GVR 的映射叫做 RESTMapper。Kubernetes 定义了 RESTMapper 接口并带默认带有实现 DefaultRESTMapper。
关于 kubernetes API 的详细规范请参考 API Conventions
如何储存
经过上一章节的研究,我们已经知道了 kubernetes API 的组织结构以及背后的设计原理,接下来我们来看看,Kubernetes API 的资源对象最终是怎么提供可靠存储的。之前也提到了 API-Server 是无状态的,它需要与分布式存储系统 etcd 交互来实现资源对象的持久化操作。从概念上讲,etcd 支持的数据模型是键值(key-value)存储。在 etcd2 中,各个 key 是以层次结构存在,而在 etcd3 中这个就变成了平级模型,但为了保证兼容性也保持了层次结构的方式。
在 Kubernetes 中 etcd 是如何使用的呢?实际上,etcd 被部署为独立的部分,甚至多个 etcd 可以组成集群,API-Server 负责与 etcd 交互来完成资源对象的持久化。从 1.5.x 之后,Kubernetes 开始全面使用 etcd3。可以在 API-Server 的相关启动项参数中配置使用 etcd 的方式:
# kube-apiserver -h
...
Etcd flags:
--etcd-cafile string
SSL Certificate Authority file used to secure etcd communication.
--etcd-certfile string
SSL certification file used to secure etcd communication.
...
--etcd-keyfile string
SSL key file used to secure etcd communication.
--etcd-prefix string
The prefix to prepend to all resource paths in etcd. (default "/registry")
...
--storage-backend string
The storage backend for persistence. Options: 'etcd3' (default).
--storage-media-type string
The media type to use to store objects in storage. Some resources or storage backends may only support a specific media type and will ignore this setting. (default
"application/vnd.kubernetes.protobuf")
...
Kubernetes 资源对象是以 JSON 或 Protocol Buffers 格式存储在 etcd 中,这可以通过配置 kube-apiserver 的启动参数 --storage-media-type 来决定想要序列化数据存入 etcd 的格式,默认情况下为 application/vnd.kubernetes.protobuf 格式;另外也可以通过配置 --storage-versions 启动参数来配置每个API 分组的资源对象持久化存储的默认版本号。
下面通过一个简单的例子来看,创建一个 pod,然后使用 etcdctl 工具来查看存储在 etcd 中数据:
$ cat << EOF | kubectl create -f -
apiVersion: v1
kind: Pod
metadata:
name: webserver
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
EOF
pod/webserver created
$ etcdctl --endpoints=$ETCD_URL \
--cert /etc/kubernetes/pki/etcd/server.crt \
--key /etc/kubernetes/pki/etcd/server.key \
--cacert /etc/kubernetes/pki/etcd/ca.crt \
get /registry/pods/default/webserver --prefix -w simple
/registry/pods/default/webserver
...
10.244.0.5"
使用各种客户端工具创建资源对象然后存储到 etcd 的流程大致如下图所示:
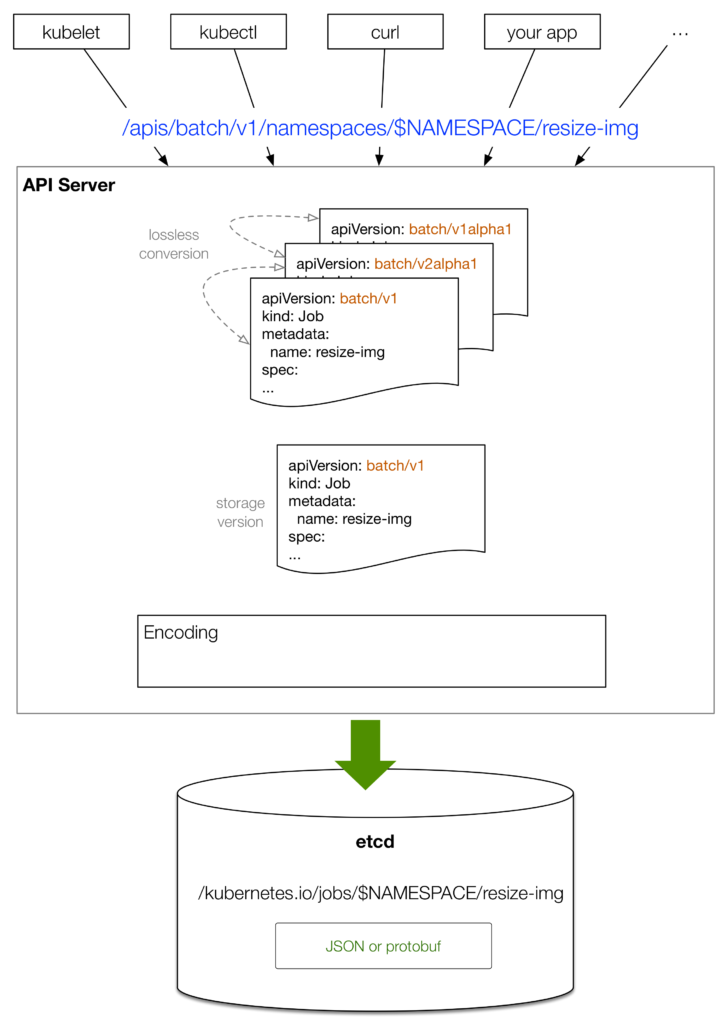
- 客户端工具(例如 kubectl)提供一个期望状态的资源对象的序列化表示,该例子使用 YAML 格式提供
- kubectl 将 YAML 转换为 JSON 格式,并发送给 API-Server
- 对应同类型对象的不同版本,API-Server 执行无损转换。对于老版本中不存在的字段则存储在 annotations 中
- API-Server 将接收到的对象转换为规范存储版本,这个版本由 API-Server 启动参数指定,一般是最新的稳定版本
- 最后将资源对象通过 JSON 或 protobuf 方式解析并通过一个特定的 key 存入etcd当中
上面提到的无损转换是如何进行的?下面使用 Kubernetes 资源对象对象 Horizontal Pod Autoscaling (HPA) 来举例说明:
$ kubectl proxy --port=8080 &
$ cat << EOF | kubectl apply -f -
apiVersion: apps/v1
kind: Deployment
metadata:
name: webserver
spec:
selector:
matchLabels:
app: webserver
template:
metadata:
labels:
app: webserver
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
EOF
$ kubectl autoscale deployment webserver --min=2 --max=5 --cpu-percent=80
$ curl http://127.0.0.1:8001/apis/autoscaling/v2beta1/namespaces/default/horizontalpodautoscalers/webserver > hpa-v2beta1.json
$ curl http://127.0.0.1:8001/apis/autoscaling/v2beta2/namespaces/default/horizontalpodautoscalers/webserver > hpa-v2beta2.json
$ diff hpa-v2beta1.json hpa-v2beta2.json
3c3
< "apiVersion": "autoscaling/v2beta1",
---
> "apiVersion": "autoscaling/v2beta2",
42c42,45
< "targetAverageUtilization": 80
---
> "target": {
> "type": "Utilization",
> "averageUtilization": 80
> }
通过上面命令的输出能够看出,即使 HorizontalPodAutoscale 的版本从 v2beta1 变为了 v2beta2,API-Server 也能够在不同的版本之前无损转换,不论在 etcd 中实际存的是哪个版本。实际上,API-Server 将所有已知的 Kubernetes 资源类型保存在名为 Scheme 的注册表(registry)中。在此注册表中,定义了每种 Kubernetes 资源的类型、分组、版本以及如何转换它们,如何创建新对象,以及如何将对象编码和解码为 JSON 或 protobuf 格式的序列化形式。
截至目前,我们了解了 Kubernetes API-Server 是什么,涉及到的基本术语,以及如何实现 API 资源的版本更迭以及 API 资源的持久化存储,接下来的笔记中,我们会从代码实现的角度进一步探讨 Kubernetes API 更详细的运行机制。