很多人应该像我一样,第一次接触 docker 的概念,都会见到或者听过下面这句话:
docker 技术比虚拟机技术更为轻便、快捷,docker 容器本质上是进程
甚至我们或多或少都在潜移默化中接受了 container 实现是基于 linux 内核中 namespace 和 cgroup 这两个非常重要的特性。那么,namespace 和 cgroup 到底是怎么来隔离 docker 容器进程的呢?今天我们就来一探究竟。
container
在了解 docker 容器进程怎么隔离之前,我们先来看看 linux 内核中的 namespace 和 cgroup 到底是什么。
namespace
如果让我们自己实现一种类似于 vm 一样的虚拟技术,我们首先会想到的是怎么解决每个 vm 的进程与宿主机进程的隔离问题,防止进程权限“逃逸”。2008年发布的 linux 内核v2.6.24带来的命名空间(namespace)特性使得我们可以对 linux 做各种各样的隔离。
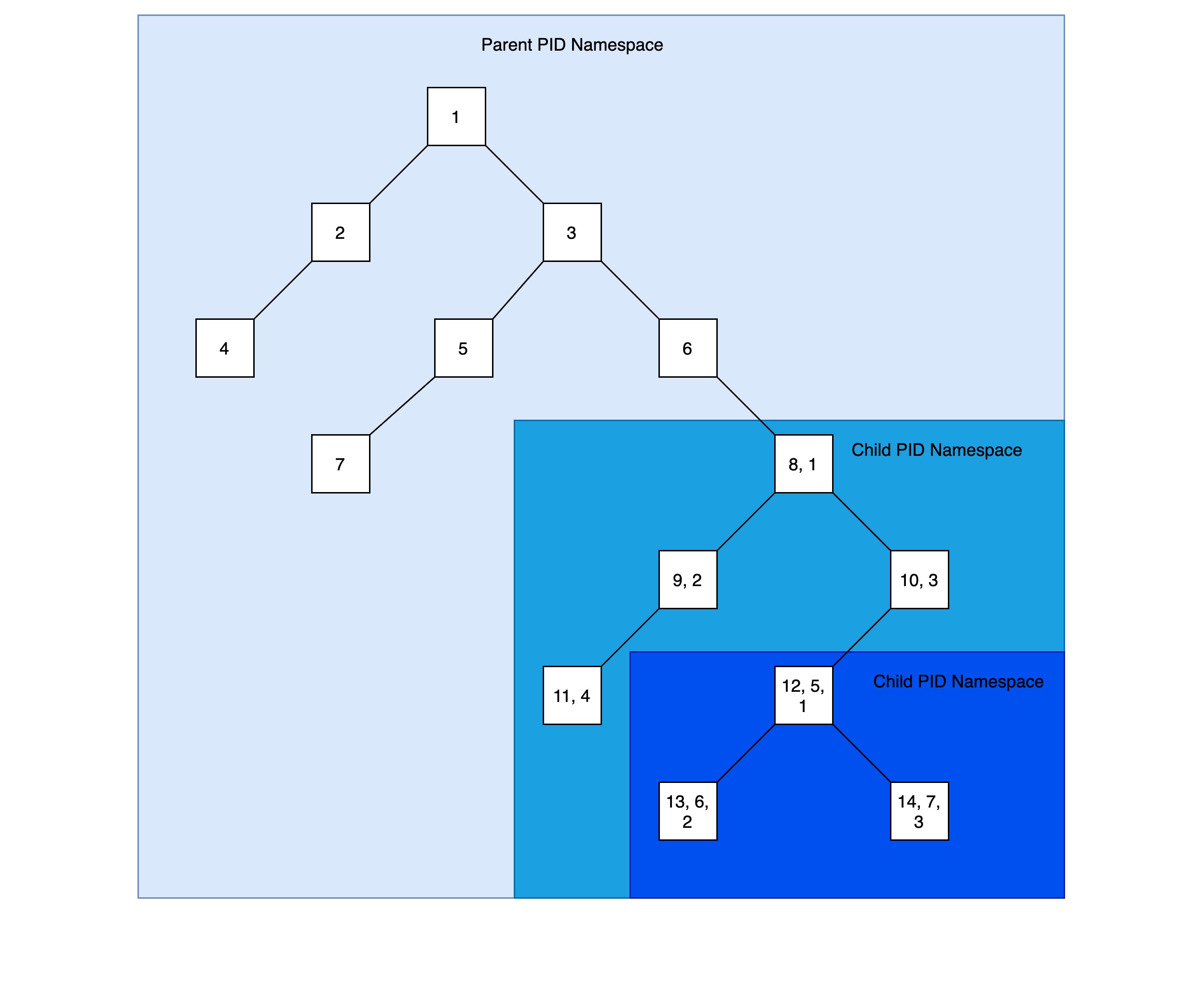
熟悉 chroot 命令的同学都应该大体能猜到 linux 内核中的 namespace 是如何发挥作用的,在 linux 系统中,系统默认的目录结构都是以根目录 / 开始的,chroot 命令用来以指定的位置作为根目录来运行指令。与此类似,了解 linux 启动流程的同学都知道在 linux 启动的时候又一个 pid 为1的 init 进程,其他所有的进程都由此进程衍生而来,init 和其他衍生而来的进程形成以 init 进程为根节点树状结构,在同一个进程树里的进程只要有足够的权限就可以审查甚至终止其他进程。这样,显然会带来安全性问题。而 pid namespace(linux namespace 的一种)允许我们创建单独的进程树,新进程树里面有自己的 pid 为1的进程,该进程一般为创建新进程树的时候指定。pid namespace 使得不同进程树里面的进程不能相互直接访问,提供了进程间的隔离,甚至可以创建嵌套的进程树:
在 linux 中,创建 namespace 很简单,只需要通过 unshare 命令并且指定创建 namespace 的类型以及其他参数,比如下面的命令就会创建新的 pid namespace 并且在其中运行 zsh:
# unshare --fork --pid --mount-proc zsh
因为 zsh 是交互式的 shell,所以你会发现自己进入了一个新的 shell,我们可以在新的世界里再运行新的进程:
# ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 8.4 0.0 42676 5684 pts/1 S 04:06 0:00 zsh
root 23 0.0 0.0 39084 3252 pts/1 R+ 04:06 0:00 ps aux
# sleep 100000
...
启动 sleep 进程前只有两个进程在运行,zsh 和 ps,而且 zsh 进程的 pid 为1,所有其他进程都是它的子进程。但是,如果你打开新的终端也可以看到 zsh 进程,但是发现它的 pid 并不是1:
# ps -ef | grep zsh
root 7180 7179 0 04:06 pts/1 00:00:00 zsh
...
# ps -ef | grep sleep
root 7851 7180 0 04:10 pts/1 00:00:00 sleep 100000
...
有此可见,通过父进程树是可以看到子进程树里面的进程,子进程树里面看不到父进程树里面的进程。但是在父进程树中看到的进程 pid 与在子进程树里面看到的该进程的 pid 不同。
事实上,除了 pid namespace,linux 内核有提供了很多不同类型的 namespace:
- Mount(mnt) namespace 可以在不影响宿主机文件系统的基础上挂载或者取消挂载文件系统了;
- PID(Process ID) 在一个pid namespace中,第一个进程的 pid 为1,所有在此 namespace 中的其他进程都是此进程的子进程,操作系统级别的其他进程不需要在此进程中;
- network(netns) namespace 会虚拟出新的内核协议栈,每个 network namespace 包括自己的网络设备、路由表等;
- IPC(Interprocess Communication) namespace 用来隔离处于不同 IPC namespace 的进程间通信资源,如共享内存等;
- UTS: UTS namespace 用于隔离 hostname 与 domainname
如果 linux 环境提供 util-linux,那么就可以通过它提供的 lsns 命令来查看当前的 linux namespace,甚至定制化输出格式:
# lsns -t pid -o NS,PID,PATH
NS PID PATH
4026531836 1 /proc/1/ns/pid
4026532445 7180 /proc/7180/ns/pid
也可以使用 nsenter 命令进入到某个 linux namespace,是不是和 docker exec 有点儿类似?
# nsenter --pid=/proc/7180/ns/pid echo $SHELL
/bin/bash
不对啊,上面的命令应该输出 zsh 才对啊,为什么会这样呢?仔细看了文档才明白原来是 nsenter 只是进入到目标 namespace,但是 SHELL 环境变量依赖于上下文,也就是说 nsenter 只是切换了 namespace,但并没有切换程序运行的上下文环境。与之对应的 docker exec 会完整的切换 namespace 和运行上下文,所以我们能够使用 docker exec 进行各种 debug 操作。
cgroup
上面提到一个进程树里面的进程不能与其他进程树里的进程交互,其实这是不完全对的。举例来说,一个进程树里面的进程会占有宿主机的资源(CPU/Memory/NetworkIO/DiskIO 等),这样有可能导致其他进程得不到足够的资源。幸亏我们可以使用 linux 内核的 cgroup 特性来限制进程能占用的资源数量,这些资源包括 CPU、内存、网络带宽、磁盘IO等。需要说明的是 namespace 和 cgroup 是两个不同的特性,上面提到的各种 namespace 有可能只用到其中的一种或者两种,与 cgroup 组合起来完成对一组进程的管理。
举个例子,通过 cgcreate 命令我们创建一个 cgroup:
# useradd morven
# cgcreate -a morven -g memory:mycgrp
通过以上命令我们创建了名为 memory:mycgrp 的 cgroup,owner 设为 morven,我们来看看 memory:mycgrp 默认的资源限制:
# ls -l /sys/fs/cgroup/memory/mycgrp/
total 0
-rw-r--r-- 1 morven root 0 Feb 4 05:02 cgroup.clone_children
--w--w--w- 1 morven root 0 Feb 4 05:02 cgroup.event_control
-rw-r--r-- 1 morven root 0 Feb 4 05:02 cgroup.procs
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.failcnt
--w------- 1 morven root 0 Feb 4 05:02 memory.force_empty
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.failcnt
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.limit_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.max_usage_in_bytes
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.slabinfo
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.tcp.failcnt
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.tcp.limit_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.tcp.max_usage_in_bytes
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.tcp.usage_in_bytes
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.kmem.usage_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.limit_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.max_usage_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.move_charge_at_immigrate
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.numa_stat
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.oom_control
---------- 1 morven root 0 Feb 4 05:02 memory.pressure_level
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.soft_limit_in_bytes
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.stat
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.swappiness
-r--r--r-- 1 morven root 0 Feb 4 05:02 memory.usage_in_bytes
-rw-r--r-- 1 morven root 0 Feb 4 05:02 memory.use_hierarchy
-rw-r--r-- 1 morven root 0 Feb 4 05:02 notify_on_release
-rw-r--r-- 1 root root 0 Feb 4 05:02 tasks
可以看到,对于内存的资源限制默认是以 bytes 为单位,我们现在来限制 memory:mycgrp 这个 cgroup 最多使用10MB的内存:
# echo 10000000 > /sys/fs/cgroup/memory/mycgrp/memory.limit_in_bytes
接下来,我们使用 memory:mycgrp 这个 cgroup 创建进程运行 java 程序:
# cgexec -g memory:mycgrp java -jar test.jar
error: Could not execute process `java -jar test.jar` (never executed)
Caused by:
Cannot allocate memory (os error 12)
可以看到,内存的限制导致我们不能以 memory:mycgrp 这个 cgroup 运行消耗内存比较大的 java 程序,直接得到 OOM 的错误信息。
实际上,除了限制进程对宿主机各种资源的消耗大小,有时候我们还需要限制进程可以进行哪些系统调用,比如说,我们要限制特定的的应用程序不能访问网络相关的系统调用,那么就需要 linux 内核提供的另外一个功能 seccomp-bpf,在此就不展开来说。
docker 容器
通过上面的介绍,我想大家应该对 docker 是如何实现资源的隔离应该有了初步的猜测,正如我们设想的一样,docker 通过为每一个容器创建 namespace 和 cgroup 的组合来实现隔离:
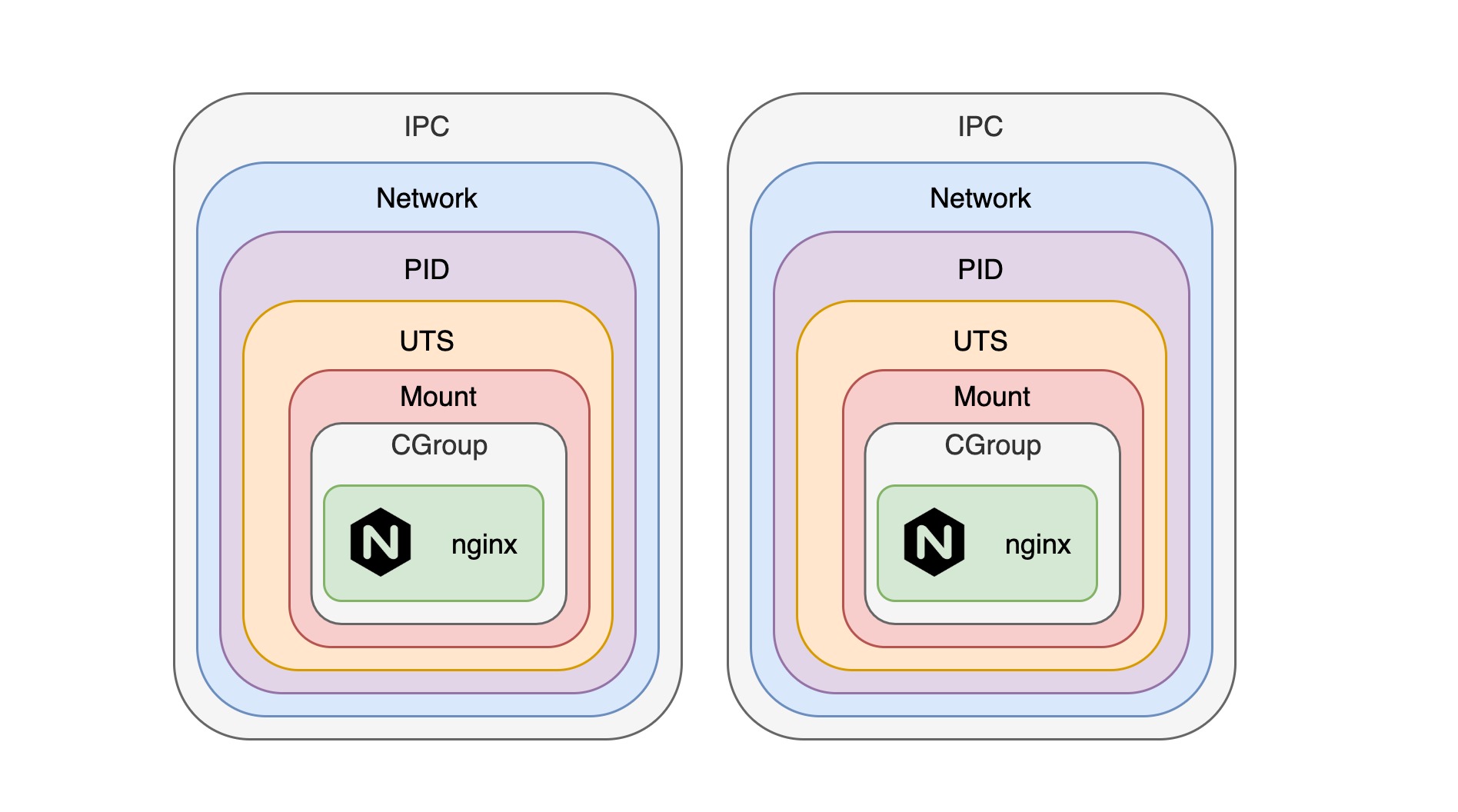
除了需要挂载宿主机的文件系统以及与宿主机做端口映射之外,每个容器实际上都是独立的 namespace 和 cgroup 的组合。但是,通过 docker 提供的一些命令行参数,我们完全可以让多个容器共享同一个 namespace,从而可以直接通信。
下面我们就举例来说,我们先创建一个 nginx 容器并使其作为一个本地代理将请求从80端口代理到 http://127.0.0.1:1313:
# cat <<EOF >> nginx.conf
error_log stderr;
events { worker_connections 1024; }
http {
access_log /dev/stdout combined;
server {
listen 80 default_server;
server_name example.com www.example.com;
location / {
proxy_pass http://127.0.0.1:1313;
}
}
}
EOF
# docker run -d --name nginx -v $(pwd)/nginx.conf:/etc/nginx/nginx.conf --ipc=shareable -p 8080:80 nginx
Note: 在启动 nginx 容器的时候指定
--ipc=shareable参数使得 nginx 容器的 ipc namespace 可以让其他容器共享。
接下来,我们创建一个 hugo 站点并且启动一个容器运行该站点,为了保证 hugo 容器与 nginx 容器共享相同的 namespace,我们需要在启动 hugo 容器的时候添加额外的参数来保证它与 nginx 容器共享同样的 namespace:
# docker run --rm --volume $(pwd):/src jojomi/hugo hugo new site mysite
# cd mysite
# docker run -d --name hugo -v $(pwd):/src --net=container:nginx --ipc=container:nginx --pid=container:nginx jojomi/hugo hugo server
# curl localhost:8080
<pre>
</pre>
可以看到,我们访问 http://localhost:8080/ 的时候可以看到 hugo 站点的页面,这时候 nginx 容器将本地请求代理给 hugo 容器,通过指定 namespace 参数我们可以让多个容器运行在相同的 namespace 中,这样就能保证容器之间可以互相连通,正如在下面这张图看到的这样:
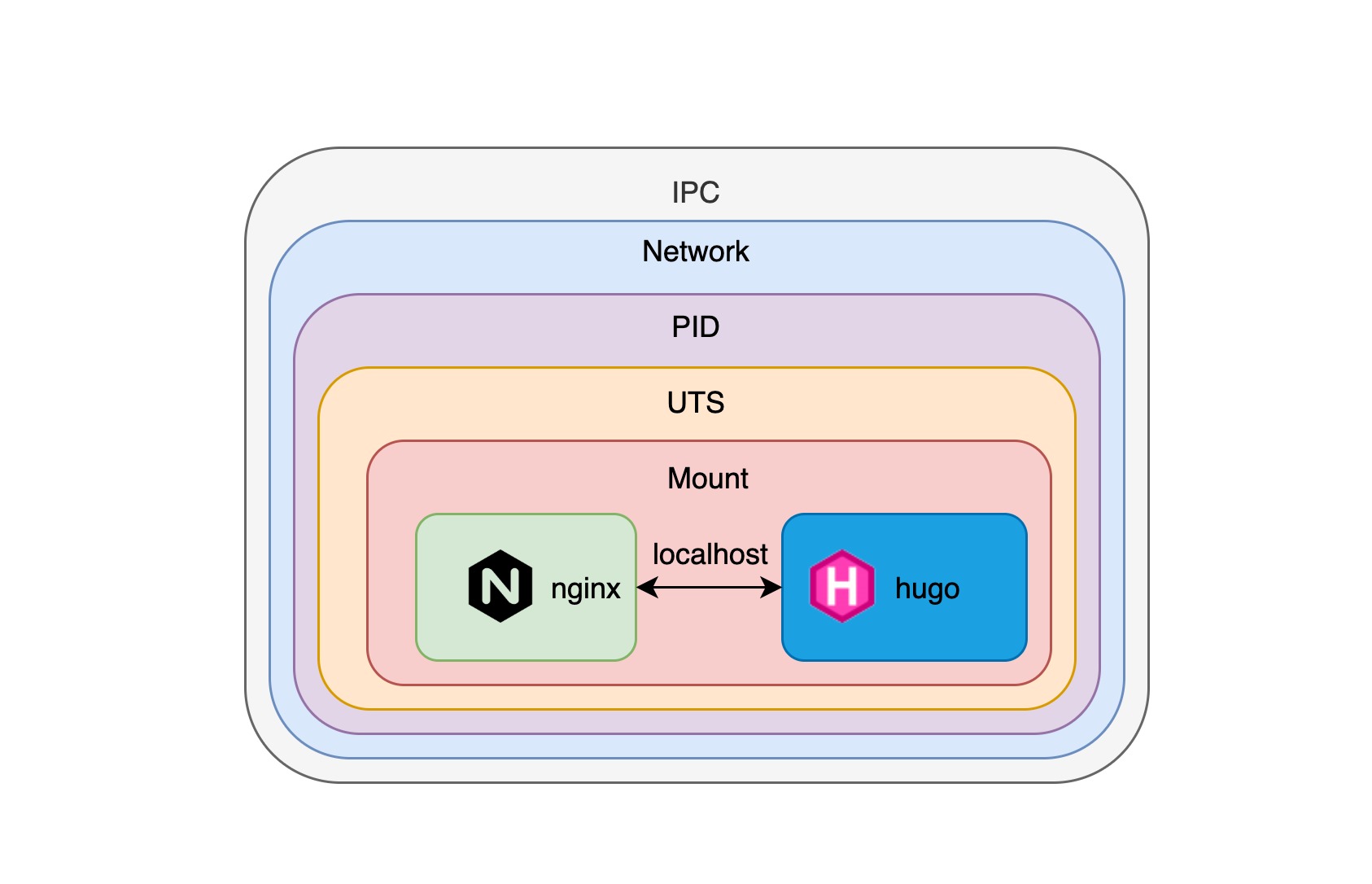
pod
既然我们可以通过组合 namespace 与 cgroup 来让多个容器进程互相连通,这不就是 k8s 对于 pod 的最基础要求吗?总的来说,pod 允许我们让多个不同的容器共享相同的 namespace 来保证这些容器进程的互相连通性,稍微不一样的地方在于,pod 使用的是 CNI(Container Network Interface) 网络标准而不是 docker 原生的网络模型。
pod 是容器的组合
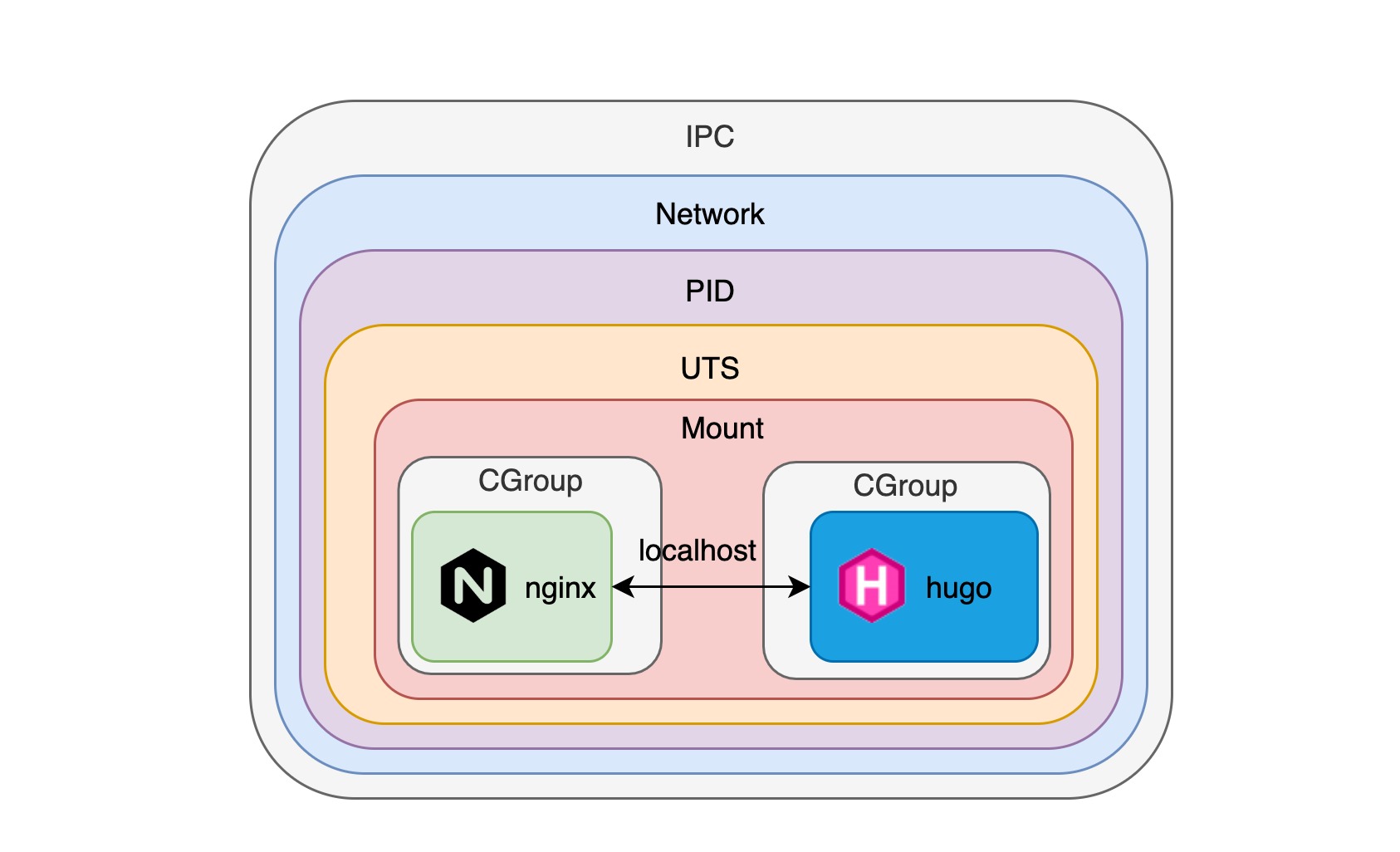
正如我们在上面这张图上看到的那样,一旦我们使用 pod 创建了这些容器,它们就像运行在同一台机器上,可以使用 localhost + 端口号直接互相访问,可以共享相同的 volume,甚至可以使用 IPC 给其他进程发送 HUP 或 TERM 等信号(Kubernetes 1.7, Docker >=1.13),详情请参考:https://kubernetes.io/docs/tasks/configure-pod-container/share-process-namespace/
但是 pod 只是将多个共享相同 namespace 的容器组合在一起这么简单么?我们看看下面一个更复杂的例子:
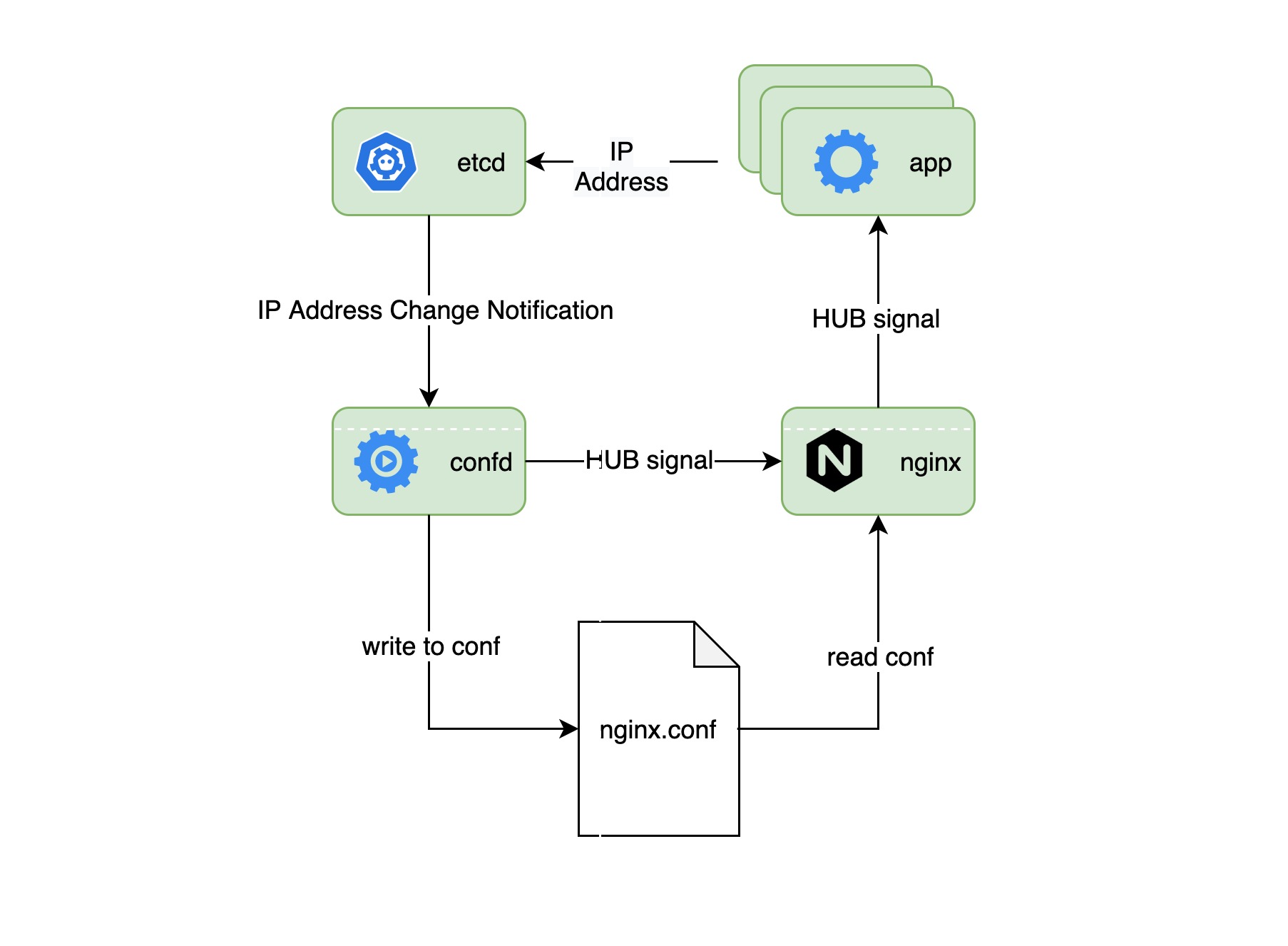
在这个例子中,nginx 作为多个应用的前段负载均衡器,它需要在每次应用的 IP 地址池变化是加载新的配置文件,我们使用 confd 来作为配置分发中心,etcd 存储着所有应用的 IP 地址池信息,并且一旦这些信息发生变化就给 confd 发送通知,从而 confd 生成新的配置文件并发送 HUB 信号给 nginx 进程来结束旧的进程,加载新配置文件来启动新的 nginx 进程。
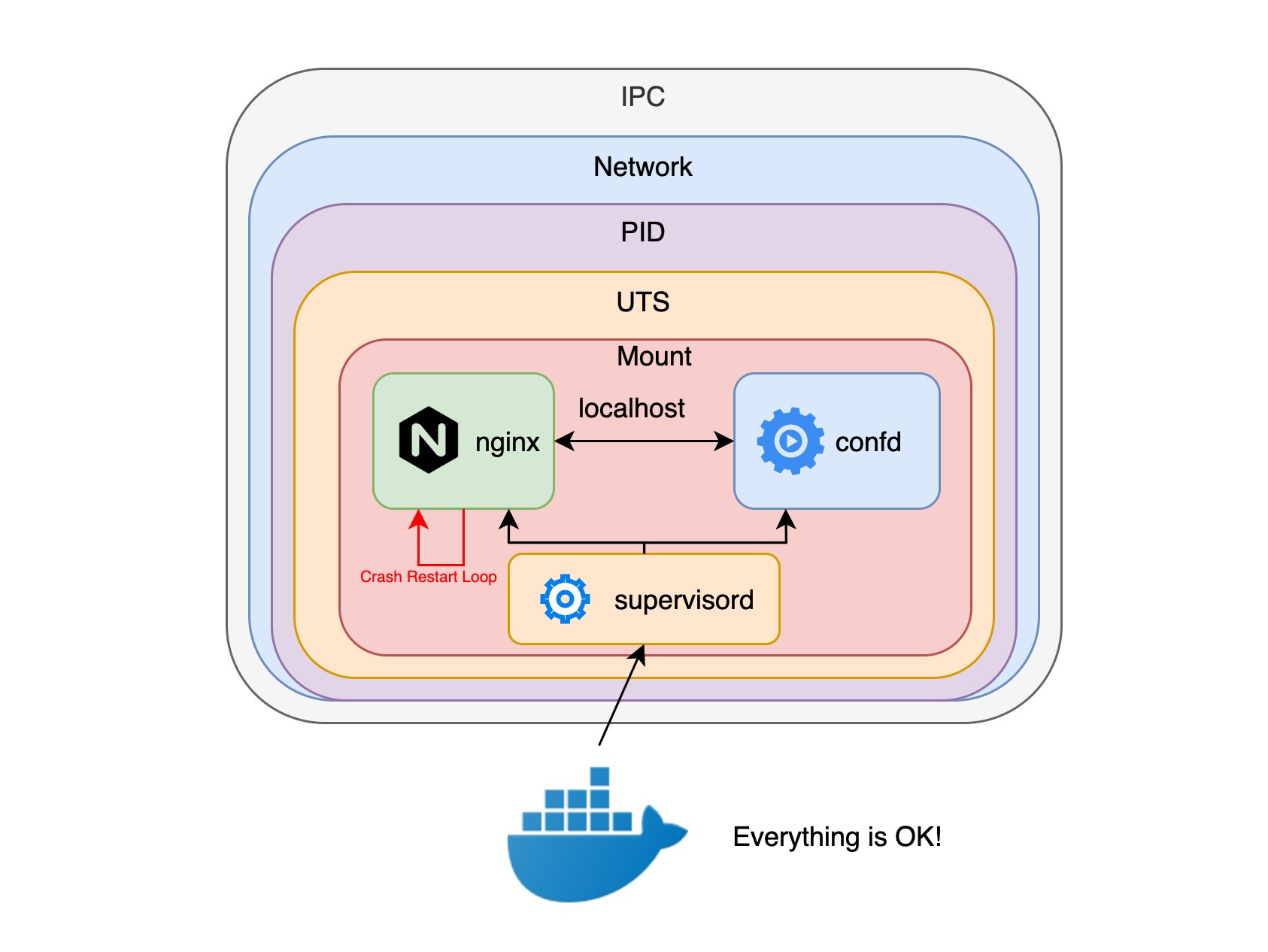
如果使用 docker 容器,我们首先想到的就是将 confd 和 nginx 进程放到同一个docker容器中,但是 docker 容器只允许一个执行入口点(entrypoint),这样我们就不得不创建一个 supervisord 进程来创建和管理 confd 和 nginx 进程,但问题是 nginx 进程需要不断重启,更重要的是通过 容器探针 API 只能知道 supervisord 进程的健康状况,confd 和 nginx 进程是否在正常运行是没法监测到的。
但是如果分别使用不同的容器运行 confd 和 nginx 进程并把它们放入到一个 pod 中,pod 就可以检测每个进程的健康状况,这是因为 pod 可以充分利用每个容器探针 API 获取容器进程的运行状况,然后在每个进程异常退出的时候尝试重启容器进程,也可以获取每个容器的日志信息。
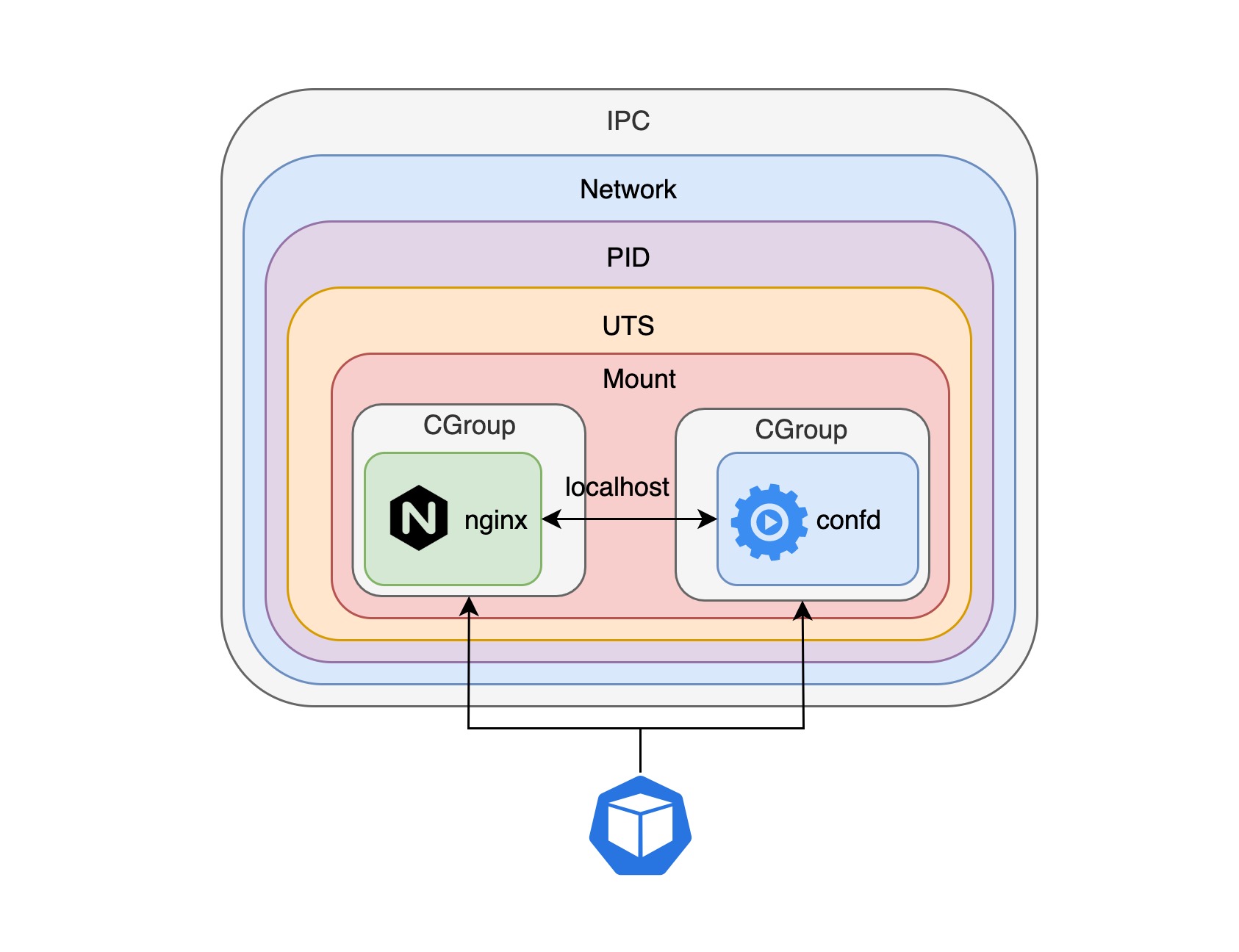
通过将多个不同的容器放入到一个 pod 中,每个容器甚至不知道其他容器的存在,就像我们在上面这个例子中看到的那样,confd 容器不知道 nginx 容器的存在,它只知道需要监听 etcd 中存储的应用 IP 地址池信息,当这些信息发生变化的时候生成新的配置并且发送 HUB 信号给特定的进程。实际上,与 confd 容器一起运行的容器不一定是 nginx 容器,它可以是任意的应用容器,这样 confd 容器的就变成了一个通用的配置分发容器,在 k8s 的概念里,这样的容器叫做 sidecar,如果你熟悉 istio,你一定对这个概念不陌生,istio 使用 sidecar 监管微服务的网络流量,进而实现类似流量路由、策略执行以及认证授权等复杂的功能。
神奇的 pause 容器
如果我们在一台 k8s 集群的节点上运行 docker ps 命令,就会发现很多含有关键字 pause 的容器:
# docker ps
CONTAINER ID IMAGE COMMAND ...
...
3b45e983c859 gcr.io/google_containers/pause-amd64:3.0 "/pause" ...
...
dbfc35b00062 gcr.io/google_containers/pause-amd64:3.0 "/pause" ...
...
c4e998ec4d5d gcr.io/google_containers/pause-amd64:3.0 "/pause" ...
...
这些 pause 容器到底是什么?为什么一个节点上有这么多 pause 容器?
通过前面的介绍我们知道 docker 容器非常适合运行单一程序,但是要将几个程序组合在一个 docker 容器里面就会很笨重,相反,将他们拆分到不同的容器中并使用 pod 来组合这些容器是最有效的做法。但是,这些在同一个 pod 中的多个容器进程谁来创建最初的 namespace 呢,看起来谁都可以,但谁都不合适;更重要的是怎样对这些容器进程进行生命周期管理呢,我们知道 pid 为1的进程是整个 pod 进程树的根结点,它负责对其他进程的管理,包括僵尸进程的回收。
可能你已经猜到了,没错,在 k8s 中,正是 pause 容器充当每个 pod 中初始的容器,由它来创建 namespace 并且负责管理其他容器进程的生命周期。
我们就来看看怎么使用 pause 容器从零开始创建一个 pod 并且共享 namespace,首先我们先启动 pause 容器:
# docker run -d --name pause --ipc=shareable -p 8080:80 gcr.io/google_containers/pause-amd64:3.0
Note: 注意我们在启动 pause 容器的时候做了8080端口到80端口的映射,这是因为接下来 nginx 容器需要使用 pause 容器初始化的网络暴露 nginx 服务。
接下来我们使用 pause 容器的 namespace 创建一个 nginx 容器并使其作为一个本地代理将请求从80端口代理到 http://127.0.0.1:1313:
# cat <<EOF >> nginx.conf
error_log stderr;
events { worker_connections 1024; }
http {
access_log /dev/stdout combined;
server {
listen 80 default_server;
server_name example.com www.example.com;
location / {
proxy_pass http://127.0.0.1:1313;
}
}
}
EOF
# docker run -d --name nginx -v $(pwd)/nginx.conf:/etc/nginx/nginx.conf --net=container:pause --ipc=container:pause --pid=container:pause -p 8080:80 nginx
接下来,我们创建一个 hugo 站点并且启动一个容器运行该站点,为了保证 hugo 容器与 nginx 容器共享相同的 namespace,我们需要在启动 hugo 容器的时候添加额外的参数来保证它与 nginx 容器共享同样的 namespace:
# docker run --rm --volume $(pwd):/src jojomi/hugo hugo new site mysite
# cd mysite
# docker run -d --name hugo -v $(pwd):/src --net=container:pause --ipc=container:pause --pid=container:pause jojomi/hugo hugo server
# curl localhost:8080
<pre>
</pre>
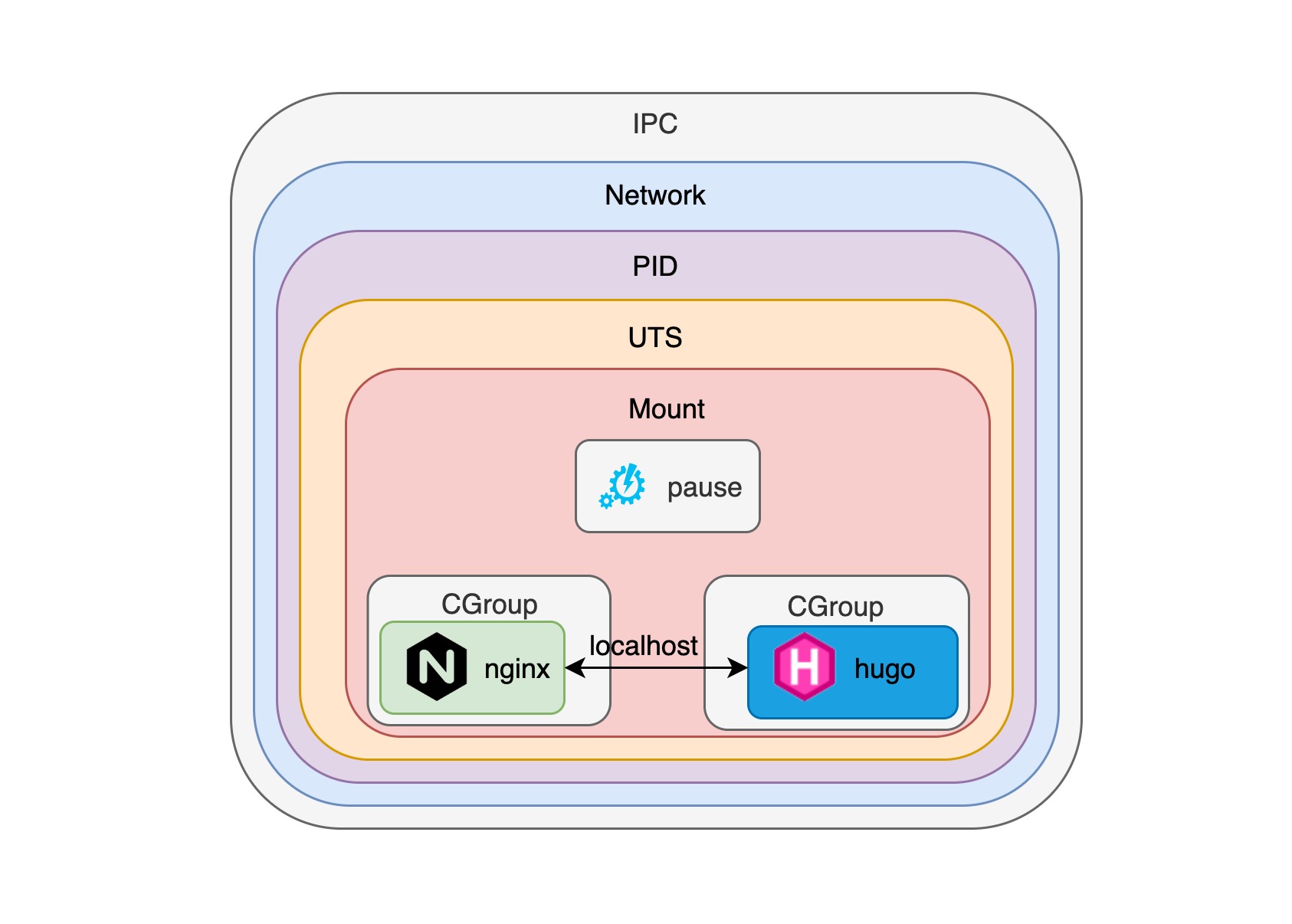
这样,就能保证 hugo 与 nginx 容器进程同时使用 pause 容器创建的 namespace,并且各个容器之间可以使用 localhost 直接通信,从而使 nginx 可以代理请求给 hugo 容器。事实上,关于 pause 容器怎么进行各个容器进程的生命周期管理也是非常值得讨论的话题,我们后续有机会的话详细来说。