字符编码问题看似无关紧要,常常被忽略,但是如果对字符编码知识没有一个系统完整的认识,在实际编码过程中我们就会遇到各种“坑”。今天,我们就来详细看看字符编码。
一切的起源
字符编码主要是解决如何使用计算机的方式来表达特定的字符,但是有计算机基础理论知识的人都知道,计算机内部所有的数据都是基于二进制,每个二进制位(bit)有0和1两种状态,我们可以组合多个二进位来表达更大的数值,例如八个二进制位就可以组合出256种状态,这被称为一个字节(byte)。这就是说,我们可以用一个字节来映射表示256种不同的状态,如果每一个状态对应一个符号,就是256个符号,从 00000000 到 11111111,这样就建立了最初的计算机数值到自然语言字符最基本的映射关系。上个世纪60年代,美国国家标准协会 ANSI 制定了一个标准,规定了常用字符的集合以及每个字符对应的编号,这就是字符编码最初的形态 ASCII 字符集,也称为 ASCII 码。ASCII 码规定了英语字符与二进制位之间的对应关系。
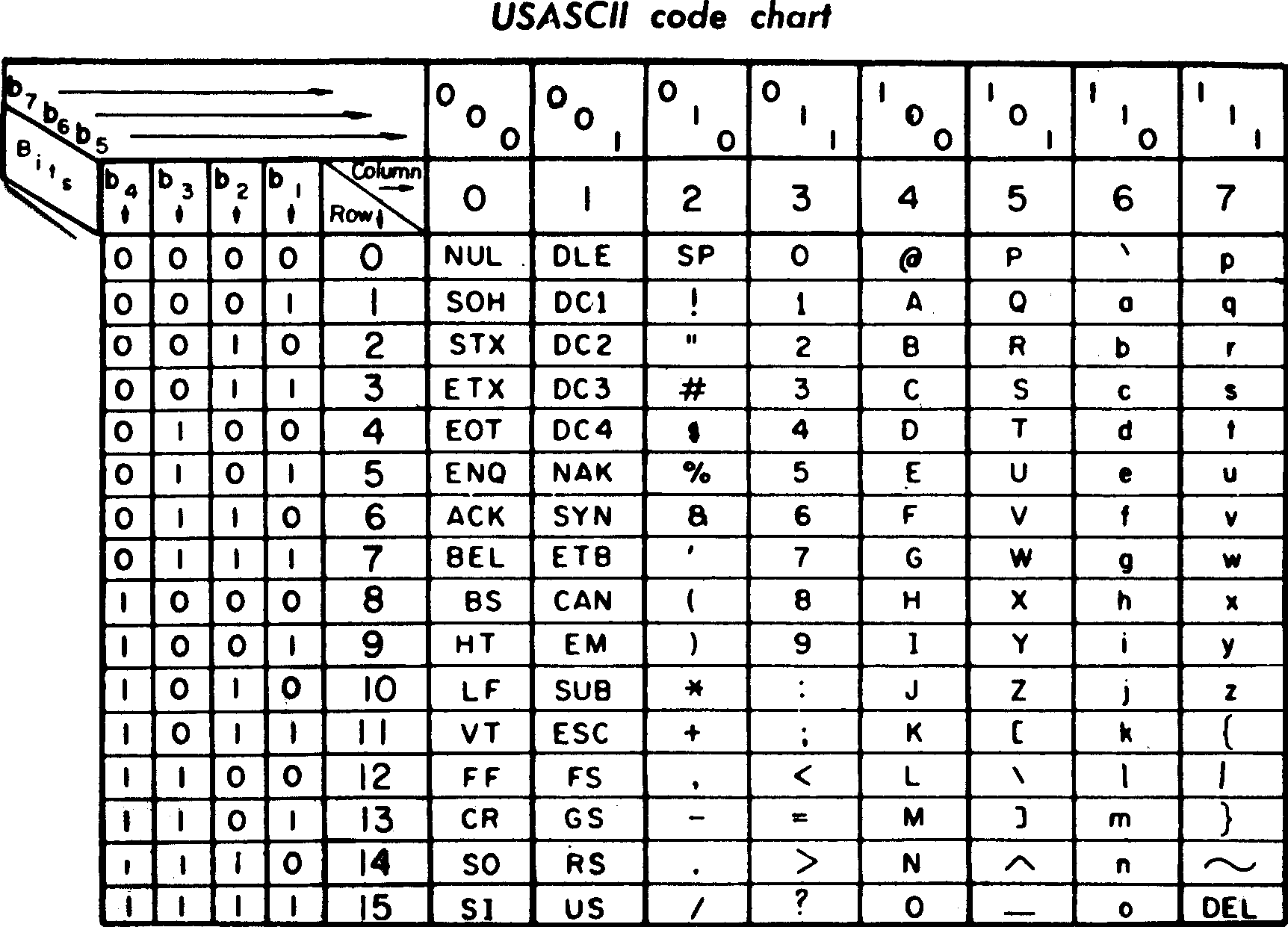
ASCII码一共规定了128个字符的编码(包括32个不能打印出来的控制符号),比如空格 SPACE 的ASCII 码是32(二进制表示为 00100000),大写的字母 A 的ASCII 码是65(二进制表示为 01000001)。这128个符号只需要占用了一个字节的后面7位,最前面的一位统一规定为0。
按照 ASCII 字符集编码和解码就是简单的查表过程。例如将字符序列编码为二进制流写入存储设备,只需要在 ASCII 字符集中依次找到字符对应的字节,然后直接将该字节写入存储设备即可,解码二进制流就是相反的过程。
各种 OEM 编码的衍生
当计算机发展起来的时候,人们逐渐发现,ASCII 字符集里的128个字符不能满足他们的需求。在英语国家,128个字符编码足矣,但是对于非英语国家,人们无法在 ASCII 字符集中找到他们的基本字符。比如,在法语中,字母上方有注音符号,它就无法用 ASCII 码表示。于是有些人就在想,ASCII 字符只是使用了一个字节的前128个变换,后面的128位完全可以利用起来,于是一些欧洲国家就决定,利用字节中闲置的最高位编入新的符号。比如,法语中的 é 的编码为130(二进制 10000010)。这样一来,这些欧洲国家使用的编码体系,可以表示最多256个符号。
但是,这里又出现了新的问题。不同的国家有不同的字母,因此,哪怕它们都使用256个符号的编码方式,代表的字母却不一样。比如,130在法语编码中代表了 é,在希伯来语编码中却代表了字母 Gimel (ג),在俄语编码中又会代表另一个符号。不同的 OEM 字符集导致人们无法跨机器传播交流各种信息。例如甲发了一封简历 résumés 给乙,结果乙看到的却是 rגsumגs,因为 é 字符在甲机器上的 OEM 字符集中对应的字节是 0×82,而在乙的机器上,由于使用的 OEM 字符集不同,对 0×82 字节解码后得到的字符却是 ג。
但是尽管出现了不同的 OEM 编码,所有这些编码方式中,0到127表示的符号是一样的,不一样的只是128到255这一段代表的字符。
至于亚洲国家的文字,使用的符号就更多了,汉字就多达10万左右。一个字节只能表示256种符号,肯定是不够的,就必须使用多个字节表达一个符号。比如,简体中文常见的编码方式是 GB2312,使用两个字节表示一个汉字,所以理论上最多可以表示 256x256,也就是65536个汉字。
Note: 中文编码的问题很复杂,这篇笔记不作深入讨论,但需要指出的是虽然都是用多个字节表示一个符号,但是 GB 类的汉字编码与后文的 unicode 和 UTF-8 编码方案是没有关系的。
从 ANSI 标准到 ISO 标准
不同 ASCII 衍生字符集的出现,让文档交流变得非常困难,因此各种组织都陆续进行了标准化过程。例如美国 ANSI 组织制定了 ANSI 标准字符编码,ISO 组织制定的各种 ISO 标准字符编码,还有各国也会制定一些国家标准字符集,例如中国的 GBK、GB2312、GB18030 等。
每台计算机的操作系统都会预装这些标准的字符集还有平台专用的字符集,这样只要使用标准字符集编写文档就可以达到很高的通用性。例如用 GB2312 字符集编写的文档,在中国大陆内的任何机器上都能正确显示。当然,也可以在一台计算机上阅读多个不同国家语言的文档,但是前提是计算机必须得安装该文档使用的字符集。
unicode 的出现
虽然通过使用不同字符集,我们可以在一台计算机上查阅不同语言的文档,但是仍然无法解决一个问题:在一份文档中显示所有字符。那时的人们就在想,如果有一种编码,能够映射世界上所有的语言符号,每一个符号都给予一个无二义的编码,那么乱码问题就会消失。这就是 unicode 字符集,就像它的名字一样,这是一种所有符号的编码。

unicode 字符集包括了目前人类使用的所有字符,当然是一个很大的集合,现在的规模可以容纳100多万个符号。每个符号的编码都不一样,比如,U+0639 表示阿拉伯字母 Ain,U+0041 表示英语的大写字母 A,U+4E25 表示汉字严。unicode 字符集将所有字符按照使用上的频繁度划分为17个层面,每个层面上有2^16即65536个字符空间。具体的符号对应表,可以查询 unicode 官网,或者专门的汉字对应表。
unicode 的问题
有了 unicode 编码方案之后,人们常会问一个问题?
unicode 是需要两个字节存储吗?
其实 unicode 只是定义了一个庞大的、全球通用的字符集,并为每个字符规定了唯一确定的二进制代码,却没有规定这个二进制代码应该如何存储。
例如,汉字严的 unicode 编码是十六进制数 #4E25,转换成二进制数足足有15位(100111000100101),也就是说,这个符号的表示至少需要2个字节。表示其他更大的符号,可能需要3个字节或者4个字节,甚至更多。
这样就会出现两个严重的问题,第一个问题是,如何才能区别 unicode 和 ASCII?计算机无法知道三个字节是表示一个字符,还是分别表示三个字符。第二个问题是,英文字母只用一个字节表示就够了,但是如果按照 unicode 编码,每个符号用三个或四个字节表示,那么每个英文字母前都必然有二到三个字节全是0,这对于存储来说是极大的浪费,文本文件的大小会因此大出二三倍,这是无法接受的。
它们造成的结果是:
- 出现了 unicode 的多种存储方式,也就是说有许多种不同的二进制格式,可以用来表示 unicode
- unicode 在很长一段时间内无法推广,直到互联网的出现。
UTF-8 的问世
随着互联网的普及,人们强烈需要一种统一的 unicode 的编码方案。UTF-8 就是在互联网上使用最广的一种 unicode 的编码实现方式。其他实现方式还包括 UTF-16(字符用两个字节或四个字节表示)和 UTF-32(字符用四个字节表示),不过在互联网上基本不用。
由于 UCS-2/UTF-16 对于 ASCII 字符使用两个字节进行编码,存储和处理效率相对低下,并且由于 ASCII 字符经过 UTF-16 编码后得到的两个字节,高字节始终是 0×00,很多 C 语言的函数都将此字节视为字符串末尾从而导致无法正确解析文本。因此 UTF-16 刚推出的时候遭到很多西方国家的抵触,大大影响了 unicode 的推行。后来聪明的人们发明了 UTF-8 编码才彻底解决了这个问题。
Note:一定要记住,UTF-8 是 unicode 的编码实现方式之一。
UTF-8 最大的特点,就是它是一种“变长”编码方式。它可以使用1到4个字节表示一个符号,根据不同的符号而变化字节长度。
UTF-8 编码规则简单实用:
- 对于单字节的符号,字节的第一位设为0,后面7位为这个符号的 unicode 码。因此对于英文字母,UTF-8 编码和 ASCII 编码是完全相同的;
- 对于 n 字节的符号(n>1),第一个字节的前 n 位都设为
1,第 n+1 位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的 unicode 码;
下表总结了编码规则,字母 x 表示可用编码的位:
| Unicode符号范围 | UTF-8编码方式 |
|---|---|
| 十六进制表示 | 二进制表示 |
| 0000 0000-0000 007F | 0xxxxxxx |
| 0000 0080-0000 07FF | 110xxxxx 10xxxxxx |
| 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx |
| 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx |
基于上表,解读 UTF-8 编码就非常简单。如果一个字节的第一位是0,则这个字节单独就是一个字符;如果第一位是1,则连续有多少个1,就表示当前字符占用多少个字节。
还是以汉字严为例,演示如何实现 UTF-8 编码:
严的 unicode 码是 #4E25(二进制表示为 100111000100101),根据上表,可以发现 4E25 处在第三行的范围内(0000 0800 - 0000 FFFF),因此严的 UTF-8 编码需要三个字节,即格式是1110xxxx 10xxxxxx 10xxxxxx。然后,从严的最后一个二进制位开始,依次从后向前填入格式中的x,多出的位补0。这样就得到了,严的UTF-8编码是 11100100 10111000 10100101,转换成十六进制就是 E4B8A5。
乱码问题分析
所谓“乱码”是指应用程序显示出来的字符文本无法用任何语言去解读,通常会包含大量 ? 或 �。乱码问题是所有人或多或少会遇到的问题,造成乱码的根本原因就是因为使用了错误的字符编码去解码字节流,所以想要解决乱码问题,我们就先要搞清楚应用程序当前使用的字符编码是什么。
比如最常见的网页乱码问题。如果遇到这样的问题,我们需要检查以下原因:
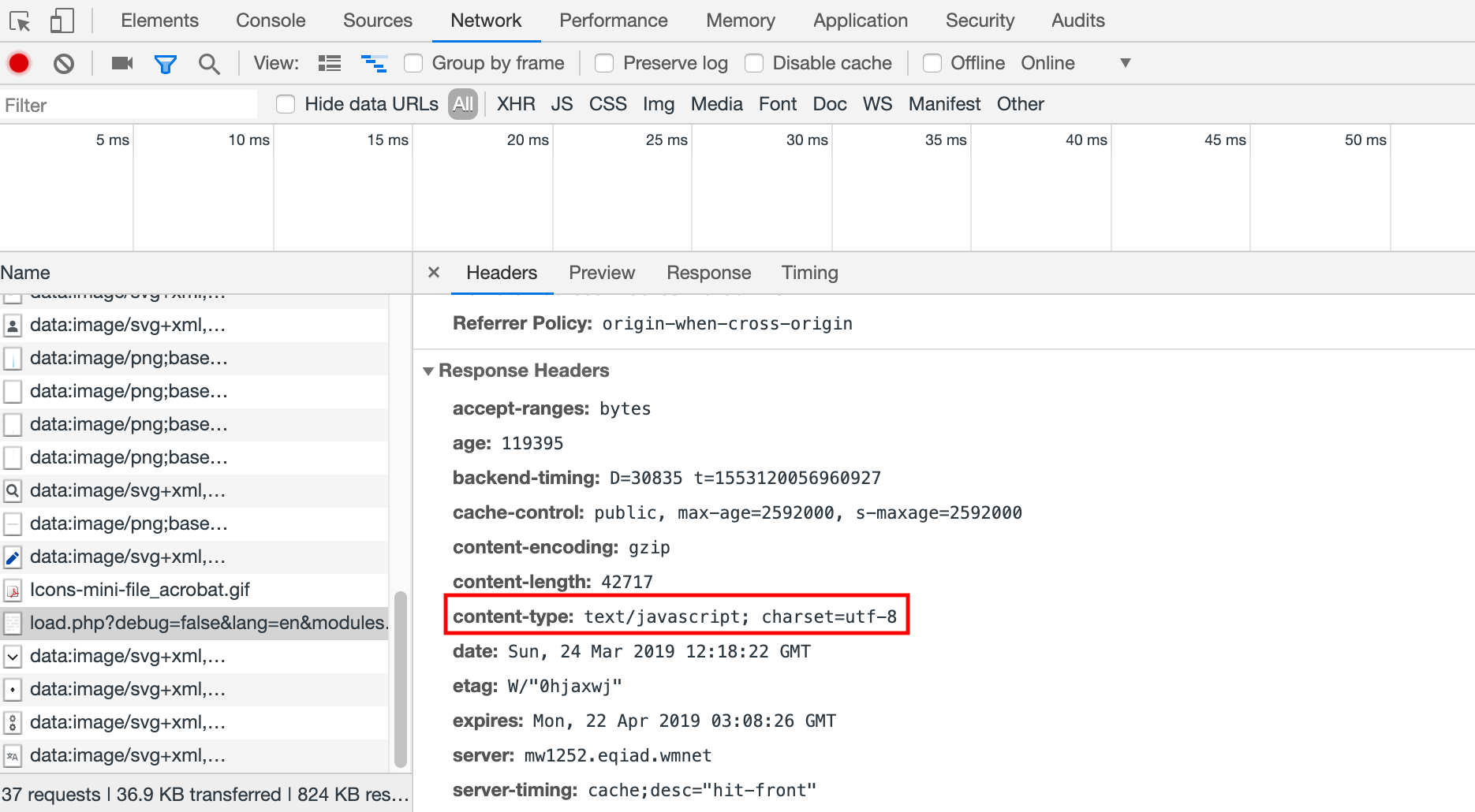
- 服务器返回的响应头
Content-Type没有指明字符编码 - 网页内是否使用
META HTTP-EQUIV标签指定了字符编码 - 网页文件本身存储时使用的字符编码和网页声明的字符编码是否一致
Note:当应用程序使用特定字符集解码字节流时,一旦遇到无法解析的字节流时,就会用
?或�来替代。所以,如果最终解析得到的文本包含这样的字符乱码字符,而又无法得到原始字节流的时候,说明正确的信息已经彻底丢失了,尝试任何字符编码都无法从这样的字符文本中还原出正确的信息来。